Text clusters: Fighting spam content using neural networks and unsupervised ML – Part 2
In the part 1 of this blog series, we discussed the data science behind our new text clustering feature, as well as the work to identify the opportunity for this product. In this post, we’ll be talking about the decisions we made and lessons we learned while designing and building the systems needed to enable this feature.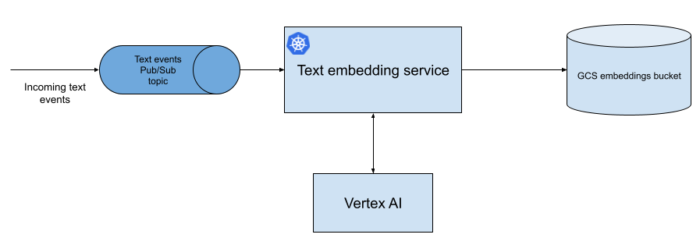
Once we identified the efficacy of using embeddings to discover clusters of fraudulent content, we began building a pipeline to do this at scale. Our first task was building a pipeline that would generate text embeddings using Bidirectional Encoder Representations from Transformers (BERT). The first prototype used a fork of bert-as-a-service, but we soon realized we wanted more flexibility on the embedding model than this project provided, so we developed a microservice in Python running a 🤗 Transformers model. Sift, being a Java-first company, had fewer services running on Python, so we opted for a simple containerized service hosted in Google’s managed Kubernetes offering, GKE. You can read about our migration from AWS to Google Cloud in a previous blog series. This service was designed to be decoupled from our live services through Pub/Sub, writing its results to GCS, which gave us greater flexibility to try new systems like GKE and Dataflow without affecting our existing production systems, as well as to develop each part of the embedding platform independently in iterative milestones.
Prototyping with GKE
Since we had completed a full migration to Google Cloud, we wanted to make use of Google Kubernetes Engine. One of the design goals for this project was to use managed solutions wherever possible, as we are in the business of creating great ML systems, not managing machine infrastructure. While GKE is managed, we found it to be less plug-and-play than we were hoping.
We found that private clusters, which are locked-down clusters that aren’t exposed to the public internet, are surprisingly more challenging to set up, and were less well documented at the time. Turning on private cluster mode for GKE also had much stricter firewall and IAM settings, which meant that basic k8s functionality was broken until we manually opened several ports and set up several IAM roles, requiring much trial and error. Given that those permissions would be required to run any workloads on GKE, we would have expected that those firewall rules and roles would have been set up automatically. For example, we needed to open certain ports from the Kubernetes master node to the node pool ports, to allow Kubernetes CRDs and custom controllers to work properly.
Another best practice for GKE is to use workload identities, which are GCP IAM identities linked to Kubernetes service account identities. They allow you to have strong permissions on your services, without needing to manage secrets or keys. We tried to move entirely to using these and away from OAuth scopes, but found that our cluster could not pull images from GCP’s container registry due to lack of permissions. Only when going through GCP support and re-enabling the OAuth storage scopes were we able to pull container images.
Generating timely clusters
After generating a dataset of embeddings with the above pipeline, we still needed to
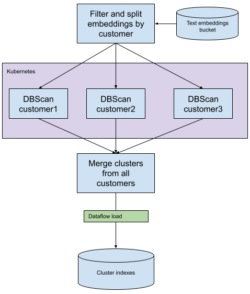
generate the clusters. We wanted to use the DBSCAN algorithm, but no Java-based libraries were available for this clustering algorithm, so we had the choice to implement them ourselves, or to integrate Python into our training pipeline. We chose to integrate more tightly with Python models. We used an Airflow pipeline to orchestrate each embedding batch. First a Spark job partitions, filters, and transforms the embedding dataset. Then a Kubernetes batch job reads the partitioned embeddings and runs SKLearn DBSCAN algorithm on the embeddings. We then run a simple Dataflow job to load the embeddings into an index for serving through our API. One thing to note for this approach is each batch of clusters is discrete, meaning it doesn’t yet have a connection to or context with previous clustering batches. A future release will be addressing this by correlating these clusters between batches.
Tuning clusters
DBScan algorithm has two parameters that allow us to tune the “tightness” cluster. The main one that we worked with was the epsilon parameter, which represents the minimum “distance” that we allow embeddings to be considered within the cluster. Smaller epsilon parameters produce smaller clusters where the items in the cluster are very similar. Larger epsilon parameters produce large clusters where the items in the clusters could be less related to each other. There is a trade-off when choosing this parameter: we want to make useful clusters, where the items in the cluster are all related to each other, but not so small that they only recognize identical text as being part of a cluster. To help with this process, we created a tool to rapidly re-cluster the embeddings for a customer given an epsilon parameter and then display the text content in the cluster. We used faiss as an nearest neighbors index to allow quick lookup of nearby embeddings, so that re-clustering could be done for medium-sized datasets in only a few seconds. This allowed us to manually tune the epsilon parameter rapidly.
Comparing model serving frameworks
Our first prototype for embedding generation uses a microservice with a python model directly integrated within it. In order to modularize our pipeline, we decided to move that model to a model serving framework. Model serving frameworks are a relatively new development in the MLOps scene, they are software frameworks (often open source) purpose-built for deploying, managing, routing, and monitoring ML models. They handle model versioning as well as features such as explainability, which is becoming a must-have for any good MLOps setup.
Sift currently runs prod models using an in-house model serving system. We decided that this project was a good use case to explore model serving frameworks without affecting our production scoring pipeline.
We compared three frameworks: Seldon Serving, KFServing, and Google AI Predict (now Vertex AI predict). All three are capable of running custom containerized models, each with several model formats they support natively (e.g., TensorFlow, SKLearn, PyTorch, ONNX). Seldon Serving and KFServing are both open source projects and are a part of the Kubeflow project, whereas Google AI Predict is a managed, proprietary system.
We compared them each for performance, autoscaling, and ease of use. For the most part, they performed similarly. This is most likely because they are all essentially containerized services with a lightweight routing layer on top, so the performance differences of each should be negligible. KFServing, which is based on knative, supports autoscaling scale-to-zero out of the box, which is a nice-to-have cost saving feature for automating our model deployment system (keeping models scaled to zero until they go live). AI Platform Predict also has scale to zero, while Seldon and Vertex AI do not. We expect Vertex AI to add this feature soon to be at parity with AI Platform since it’s the spiritual successor of that product, but there are currently still some features yet to be ported over. All three products support explainability APIs, but Vertex AI edges out the others slightly because it offers this feature out of the box, as well as feature drift analysis, whereas the others require additional integration effort.
In the end, we decided to go with Vertex AI because it provides managed models for a similar price and with a similar enough set of features to the other frameworks. Again, we prefer a managed solution when possible, if it allows us to dedicate more effort to our core mission of building better ML models.
Lessons learned
In the process of implementing this project, we learned quite a few lessons. We made use of several prototypes throughout the design process, which allowed us to rapidly test out ideas and make sure the core ideas were sound before dedicating engineering resources to the project. If we were to start the project over, we might have used a model serving framework right from the start, as that provides much more flexibility in choosing different embedding models and allows us to decouple the model logic from the “glue” routing logic of the system.
We also found working with GKE to be generally good, but with some challenges that were specific to our use case. Now that we’ve worked them out, we are able to run Kubernetes services fully locked down. With those key lessons learned, we are in good shape to migrate more of our services to Kubernetes, which should allow us to move towards an autoscaled microservice model that we hope to serve Sift well into the future.
We have received a good amount of beta feedback from our customers for the new text clustering feature. We are working on incorporating customers feedback into our 2022 plan, and we’re excited to get working on it!
What’s next?
We are currently tuning our cluster selection process using several heuristics so the most relevant and most suspicious clusters are brought to the front. This is in line with our goal to make the most efficient use of human input into our system. These heuristics might be different for each customer, so we are working with our customers to find settings for each. We are also working to correlate cluster runs between batches so the context is preserved for our customers’ analysts.
Sift-wide, we’re applying what we learned from this project about model serving frameworks to move our production models from our in-house model serving system to a model serving framework. This will allow us to iterate even faster in building new models and provide more built-in insights for our model and feature performance. Stay tuned for a future blog post about that effort.