Text clusters – Fighting spam using neural networks and unsupervised ML – Part 1
The spam problem
“Spam will be a thing of the past in two years’ time” – Bill Gates in 2004.
Today, spam text plagues online platforms in many industries, including e-commerce, job listings, travel, and dating sites. Spammers often post the same or highly similar (near-duplicate) content repeatedly on a site, each with their own agendas that rarely line up with the online community’s purpose. Sometimes, a spammer has a more benign objective: aggressively promoting a service. Other times, the spam content can be quite malicious: a large-scale scam that lures a victim into financial ruin or bodily harm.
At Sift, we score more than 750 million pieces of content per month, most of which contain text content shared with us by our customers. Our Content Integrity product, using our global network, excels at finding spammy accounts, but we wanted to expand outside of that domain to other use cases, and to detect the essence of what makes spam content, spam. To do this, we needed a way to label the new types of content fraud that we wanted to detect. We asked ourselves, how can we assist our customers in discovering novel fraudulent content while also allowing us to bootstrap labels in new domains?
The result of that work is a new feature, Text Clustering, which allows our customers to discover more types of anomalous content and label large amounts of spam content at once. Below, we highlight the data science and engineering efforts used to build this feature. We will dive deeper into the challenges of productionizing of machine learning models, in the second post of this blog series, shortly.
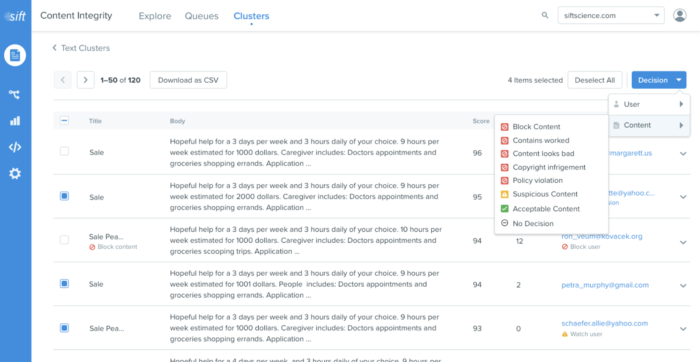
Sift Console
Analyzing our data
At an early stage of any project, our goal is to establish the solution’s customer impact and technical feasibility before investing significant engineering resources—i.e. is the problem solvable and worth solving? In a previous engineering blog, we talked about how we use our bi-annual hackathon to drive innovation at Sift. The text clustering project, which started as a hackathon project, is one example of this in action. On a high level, we started from the assumption that near-duplicate content is often suspicious. Think of the spam messages you see on a job listing site. You might see the same basic posting all over the site, advertising “earn thousands $$$ per day from the comfort of your home”, but each with slight variations in the email address or name for each post, meant to foil basic text filtering. For the hackathon, we envisioned a tool that could automatically find near-duplicate text content and surface them to Sift customers to apply bulk decisions for hundreds of pieces of content at once.
Why do we need human decisions? As it turns out, not all near-duplicate texts are necessarily spam content. For example, many different sellers will post the same popular item on an e-commerce platform, so there could be many very similar postings. Often, an important aspect of a Machine Learning (ML) product isn’t just the volume of training data, but also the quality of that data. Making efficient use of human input doing what it does well (e.g., understanding and recognizing novel patterns) feeding into the ML system, doing what ML does well (finding patterns in large amounts of data very fast and without tiring), can be more effective than trying to solve the solution using ML alone. Deciding what to reinforce in the model and what to downplay can have huge implications for the overall accuracy.
Unsupervised learning
Problems with little to no ground truth are perfect use cases for unsupervised learning, a type of machine learning where a system will look for patterns in the input data without a definitive source of truth of the “right” answer. Clustering is an unsupervised learning technique in which similar items or entities are grouped together with others that are similar to it. In the fraud space, we hypothesized that groups of very similar (near identical) text would often represent fraud, the logic being that legitimate text content is usually unique—unique enough that it would not be clustered similarly with other content. Clustering algorithms are a natural solution to the problem of grouping similar items. We can frame our use case as an unsupervised machine learning problem that consists of two sub-problems: first, we must transform the text into a learned representation that allows us to efficiently compute text similarity (an embedding), and secondly, we use a clustering algorithm to group those representations.
Multi-language sentence embedding
Computers aren’t generally native human language speakers, so we need to translate text into a form that would be understandable by a software algorithm—some numeric representation where we can easily determine if two texts are similar. One technique to find this representation is using neural nets to generate an embedding
Neural nets, which operate in layers, can be thought of to work by taking an input and progressively learning more sophisticated representations of that input for each layer in the neural net. This is directly analogous to how human sensory inputs work. For example, a bunch of light-sensitive neurons in the eye provide raw inputs to your brain, successive layers of neurons fire from this input, early layers detecting edges and shapes, later layers detecting groups of shapes and textures, until final layers of neurons fire, indicating that what you’re seeing is a dog, cat, or firetruck.

Photo of a dog
Once a neural net has been trained over some input data, the final layers of the neural network have learned a high-level representation of the input data. This learned representation contains a distillation of the useful information in the input data. The representation, which is a high-dimensional numeric vector, also often exhibits a property where vectors that are nearby spatially, correlate to similar inputs.
After surveying the industry trends and latest research development, we decided to use sentence embeddings as a vector representation of text content. Specifically, we used transformers (BERT and its variants) to convert text content into 1-D vectors. In this vector space, cosine similarity measures the semantic closeness of text content. Many clustering algorithms work in Euclidean space, and it’s straightforward to convert cosine similarity into a Euclidean one. These pre-trained embeddings give us good performance, as well as support of 100+ languages, without us having to come up with our own training data.
DBSCAN as the clustering engine
When discussing clustering algorithms, people often think of k-means as their first choice. However, we found that k-means did not fit our needs because it does not allow us to control the maximum distance within clusters, and thus we cannot control the “tightness” of the resulting clusters. For example, k-means will cluster unrelated text together simply because this group happens to be relatively isolated from the rest of the population. For our use case, we only want to find “pure” clusters, where the content is either all fraudulent or all legitimate, not a mix of both. DBSCAN allows us to control how close the samples are before grouping them, which allows us to tune the clusters to be purer. Here is an excellent write-up comparing these two algorithms.
However, the vanilla DBSCAN algorithm is very slow when applied to a large number of high dimension embedding vectors. To mitigate this problem, we leveraged the vector index engine FAISS for faster nearest-neighbor lookup and adapted the DBSCAN algorithm to work with it.
Putting the embedding and clustering algorithms together, we were able to build a convincing prototype that helped us discover numerous nefarious near-duplicate text among multiple content customers, so we decided to put this prototype into production.
In our next post, we will discuss the process of productionizing this idea. Stay tuned!