Lessons Learned From Bigtable Data Migration
(Part 4/4)
In the previous article, we discussed how we evaluated Cloud Bigtable for Sift, how we prepared our systems for the zero downtime migration from HBase, and the overall data migration strategy. In this post, we present the unknown unknowns we ran into during our data migration.
As in the previous articles, the target audience of this article is technology enthusiasts and engineering teams looking to migrate from HBase to Bigtable.

Data-migration
Our overall migration strategy was to divide and conquer: break the migration of HBase tables into sub-groups of tables depending on their access patterns; add a mechanism so the batch processing would continue to work in AWS while tables were being migrated; migrate the application services from AWS to GCP independent of the data; and, start with migrating HBase data to Bigtable over public internet first and switch to using the cloud interconnect when the interconnect became ready. More details of this process can be found in the previous article.
Half-way checkpoint
Midway through the data migration, we got the cloud interconnect to work, so we directed our AWS services to use the interconnect to access already-migrated tables, while being mindful of the 5GB/s cap on the interconnect (more on this limit in a different blog article). At this point, our system looked like this:

Real-time validation and server timestamp
The previous article describes how we setup our realtime-data validation to report read mismatches at row, column, qualifier, timestamp, and cell levels. In the validation dashboards, some tables consistently showed timestamp mismatches between HBase and Bigtable. We later realized that when a Put() is called without the client specifying a timestamp, the servers (Bigtable or HBase) picked their timestamps, which need not match between the two datastores. While this didn’t cause any correctness issues with the data, the real-time validation was unreliable for such tables. To address this, we modified our application code to always specify a timestamp in Put().
Undocumented API limitation
There was an undocumented limit (20kB) on the serialized size of value in the checkAndPut(row, col, cq, value, put) call for Bigtable HBase client. This possibly would have also affected checkAndDelete(). Some parts of our system occasionally called this API with a larger than 20kB payload, causing errors. This issue also surfaced midway through the data migration and we had to modify our application code to handle this.
Accessing historic metrics
The Stackdriver metrics and GCP console provided a lot of insights, but it was hard to see data past 6 weeks in this system. This impacted long-term trending analysis and capacity planning. At the time of writing this, we are still working with Google to get metrics beyond the 6 weeks in the past.
Handling expired data
A key difference between HBase and Bigtable is the way the expired data is handled. If a cell has expired (due to TTL or max versions), a subsequent get() or scan() from HBase will not return that cell in the result irrespective of whether compaction ran in HBase or not. On the contrary, Bigtable includes such expired cells in the get() or scan() results until they are garbage collected (GC).
This difference is amplified by the fact that Bigtable GC is opportunistic (and can sometimes take up to a week to purge cells that exceeded the TTL/max-versions).
This difference haunted us in multiple forms. Our application services started to receive more than the needed data in get() or scan() from a Bigtable table than its HBase counterpart. Our real-time validation dashboards helped to catch this, and we resolved this problem with code changes to make a get() or scan() call with a specific number of versions. We did this before switching over these tables from HBase to Bigtable.
The lazy GC in Bigtable also affected our daily backups (i.e. sequence file export). Some of the backups were failing randomly, with the error saying the row size exceeded 256MB (the Bigtable row limit). This was because the export job was including older versions of cells that have exceeded the TTL or max-versions, but haven’t been garbage collected. To prevent this error, we had to specify bigtableMaxVersions parameter in the Dataflow beam export job, to be the max of the max-versions of columns in the table.
Schema check at startup
On startup, our applications ensure that the tables in the datastore match the schema of the table defined in the code. This is normally fine, but when we deploy an application fleet of size about 100, they all startup around the same time querying the table in the datastore. In HBase this was fine, but in Bigtable, this caused an error like RESOURCE_EXHAUSTED: Quota exceeded for quota group ‘TablesReadGroup’ and limit ‘USER-100s’. Since there is no GCP configuration or quota to relax this limit, we resolved the problem by allowing only one application (i.e., the canary deployment) in each fleet to do the schema check at startup.
Mismatched expectations in system sizing
One of our HDD (slow) tables incurred a very high read rate (250MB/sec). HBase didn’t have a way to show how badly this table affected the cluster, but in Bigtable we saw the errors right away. From Bigtable documentation, it seems the HDD Bigtable is recommended to run at about 500kB/s reads per Bigtable node. Since we didn’t want to setup a large (500+ nodes) HDD Bigtable cluster to sustain 250MB/s read load, we had to migrate this table to the SSD cluster in Bigtable. This high throughput table being tens of TB in size meant that we had to revise our initial sizing and cost calculation based on SSD nodes.
A bigger issue for us was the storage utilization we get in the Bigtable cluster. Our initial cost calculations for Bigtable migration were done mainly based on data size. We were planning to operate Bigtable at around 75% storage utilization and hoping that the compute and I/O will keep up at this cluster size (as we did with HBase on comparable EC2 instances). But in reality, after data migration, our SSD Bigtable cluster runs at 25% storage utilization. If we reduce the nodes further down in the SSD cluster, we start to get client timeout errors. The HDD cluster runs at 35% storage utilization. If we reduce the cluster any smaller, we start to get disk read errors. If we had to do this all over again, we will now know to pay closer attention to more factors than just the storage utilization while sizing.
With that being said, the better observability tools of Bigtable have helped us narrow down the problem to poor schema design in some tables or bad access patterns in our application clients. We are in the process of improving them now.
Cost of Bigtable snapshots
In the previous article, we talked about how we decided to migrate our online system to GCP first while our batch processing system remained in AWS. One key component in this intermediate state is the data transfer of “table snapshots” from Google Cloud Storage (GCS) to Amazon S3. During our initial cost estimation, we didn’t factor in the cost of copying the “table snapshots” (i.e., Bigtable-exported sequence files) from GCS to S3. But due to the size of the daily backups and bandwidth constraints of the interconnect network we ended up incurring a high cost. It would have been useful if GCP/Bigtable had an incremental snapshot/backup functionality; the native snapshot support in Bigtable is still a work-in-progress in GCP at the time of writing.
During the migration, we did the following to support the batch jobs on AWS:

We used the same interconnect (that has a 5GB/s bandwidth limit) for GCS to S3 “distributed copy” (distcp) of table snapshots. This helped us to save bandwidth cost, but we still had to do the distcp less frequently to avoid affecting the online traffic going via the same interconnect in the other direction. We configured the distcp to be able to switch between the interconnect and public internet (more expensive) to give us flexibility.
Be careful if you use reverse timestamps
We ran into an interesting timestamp issue. In four of our tables, instead of writing a cell value with a timestamp represented in milliseconds since epoch, we wrote the cell value with timestamp as Long.MAX_VALUE – timeInMilliseconds (basically, “reverse timestamps”). HBase stores timestamps in milliseconds, whereas Bigtable stores it in microseconds, and both use a 64-bit signed integer for this. The HBase client for Bigtable converts a millisecond timestamp to a microsecond timestamp while writing to Bigtable, and does the conversion the other way in the read path. But this conversion does not handle the “reverse timestamp” correctly. Thankfully, we ran into this issue in our last set of tables when we saw the real-time validation results being way off. The fix for this was a bit complicated: we had to create a new column families (CF) in the source HBase table with a modified reverse timestamp, backfill data into this CF with a map-reduce job, validate the source table data integrity, drop the old CF in the source table, and then do the migration to Bigtable. See related Github issue here.
Post data-migration thoughts

Planning pays off
Investing time and effort upfront in understanding the data system, building smart monitoring tools, adding reusable tools to automate data transformations and transfers, and having a good data migration plan helped us to stay on track with the schedule.
We took about 2 months for the POC, 2 months for the migration plan, and executed the data migration in 7 months. We went 6 weeks over our original estimation, but for a migration of this scale with zero downtime for our customers, we feel this was reasonable.
The migration was seamless; during the whole duration of data migration, our external facing endpoints were not affected. Internal processes such as batch/ETL jobs and model trainings were not impacted, and there was no downtime for our customers.
Be prepared for surprises
There were surprises due to mismatched expectations in sizing the Bigtable cluster and due to data validations that we didn’t emphasize on during the proof of concept (POC) phase. This was an intentional tradeoff we made during the POC with the GCP trial credit in mind. That said, since we have a great team of resourceful engineers who are creative, willing to roll with the punches, and support each other when needed, we were able to address these surprises and keep marching forward.
Support from GCP team
Google Cloud team was very helpful in providing us guidance through the migration process, vetting our strategies with their in-house experts, and troubleshooting some Bigtable issues we faced. There is a lot of open-source activity around the GCP tools, driven by Google, and we were happy to see the level of activity there. The turnaround time for some of the issues we filed in Github was surprisingly quick. On the flip side, we were not impressed with their L1 support. We had to explain our systems multiple times to the first level support team and the quality of answers we got also left much to be desired.
Migration made Sift better
Overall, we are very happy that we migrated to Cloud Bigtable. Some of the issues that surfaced during the migration have helped us to improve our schema design and optimize the access patterns.
We get a much better visibility with Bigtable about performance hotspots, and this puts us in a good place to improve our systems.
The 99p latency observed from application services dropped significantly when we started to use Bigtable. The following graph shows a 3-day view of the latency observed for our highest throughput slow (HDD-based) table in January 2020 in blue. The red line shows the same table’s latency in April 2019.
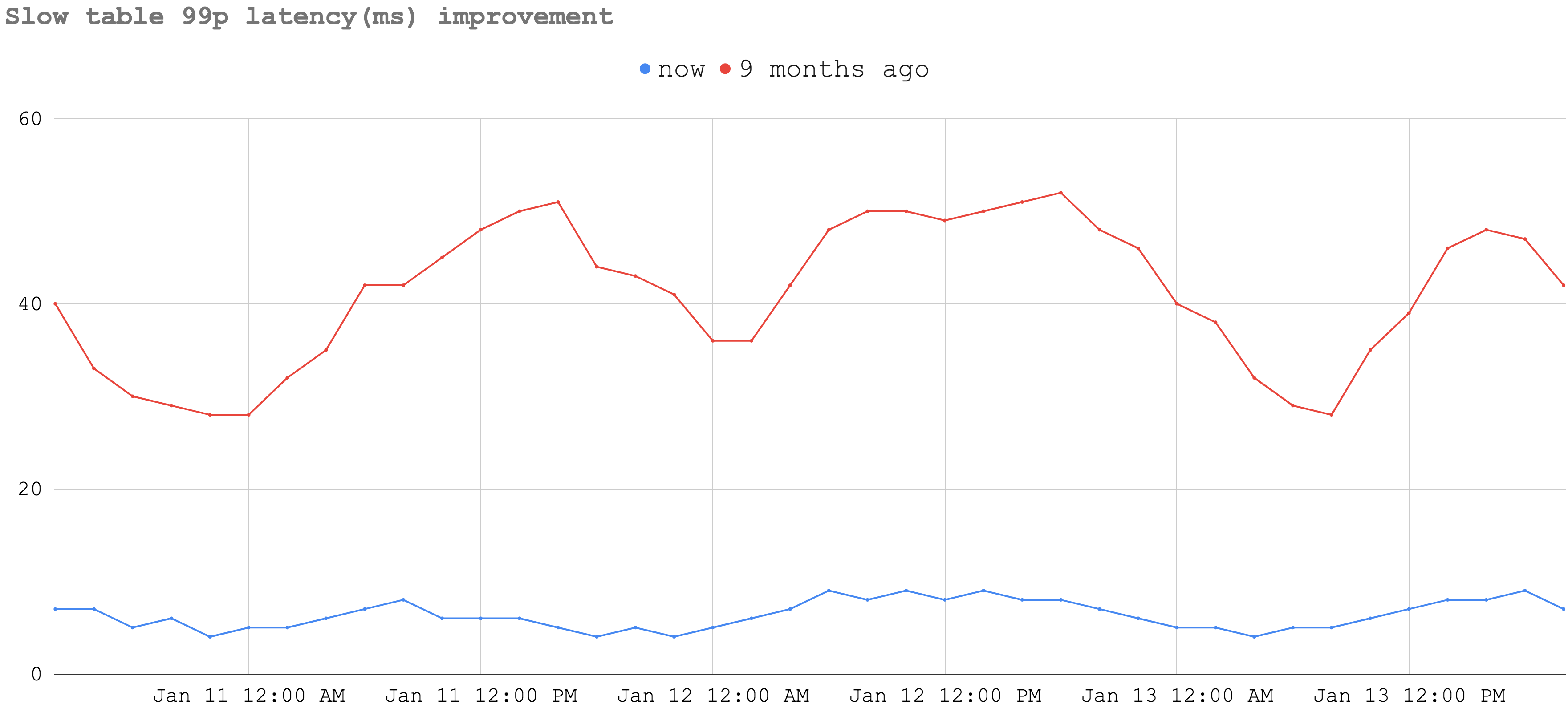
A similar effect is observed for the highest throughput fast (SSD-based) table as well:
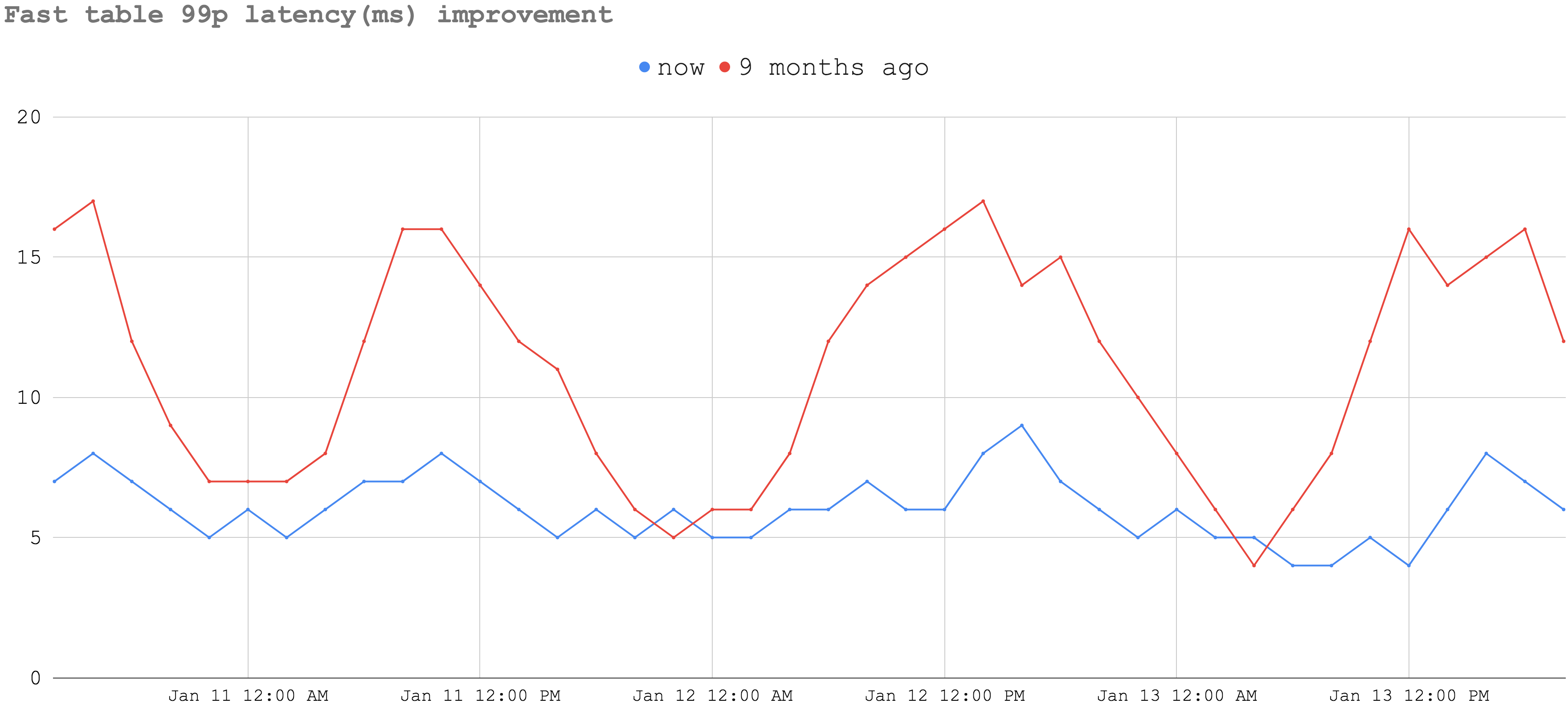
In general, the latencies observed from our applications for all tables were the same or better.
The biggest win from the migration has been the reduced operational overhead of our platform. The on-call incidents are an order of magnitude less (down from 25 HBase incidents per week in Fall 2018 to 2 minor Bigtable incidents in December 2019). We are really looking forward to continuing to scale our service using new technologies on Google’s cloud platform.