Planning a Zero Downtime Data Migration
(Part 3/4)
In the previous article, we described how we assessed the fitness of Bigtable to Sift’s use cases. The proof of concept (POC) also helped us to identify some parts of our system that needed to be modified for the migration to work seamlessly. In this article, we will discuss some of the system & code modifications, as well as the planning that went into our zero-downtime migration of HBase to Cloud Bigtable.
The target audience of this article is technology enthusiasts and engineering teams looking to migrate from HBase to Bigtable.

Dynamic datastore connectivity
During the POC, we did mirroring to Bigtable at a per-service granularity. But it was soon apparent that doing this at a per-table granularity would provide a lot more flexibility. To achieve this, we modified our DB connecter module to dynamically use HBase or Bigtable as datastore per table, and the percentages of traffic to mirror in the read and write paths. This information was kept in a Zookeeper node. Our application services used the Apache Curator client to listen to changes to this Zookeeper node. This setup enabled us to specify where live traffic goes, where duplicate traffic goes and by how much. This also gave the team the flexibility to switch between HBase and Bigtable if needed. The diagram below depicts the setup.
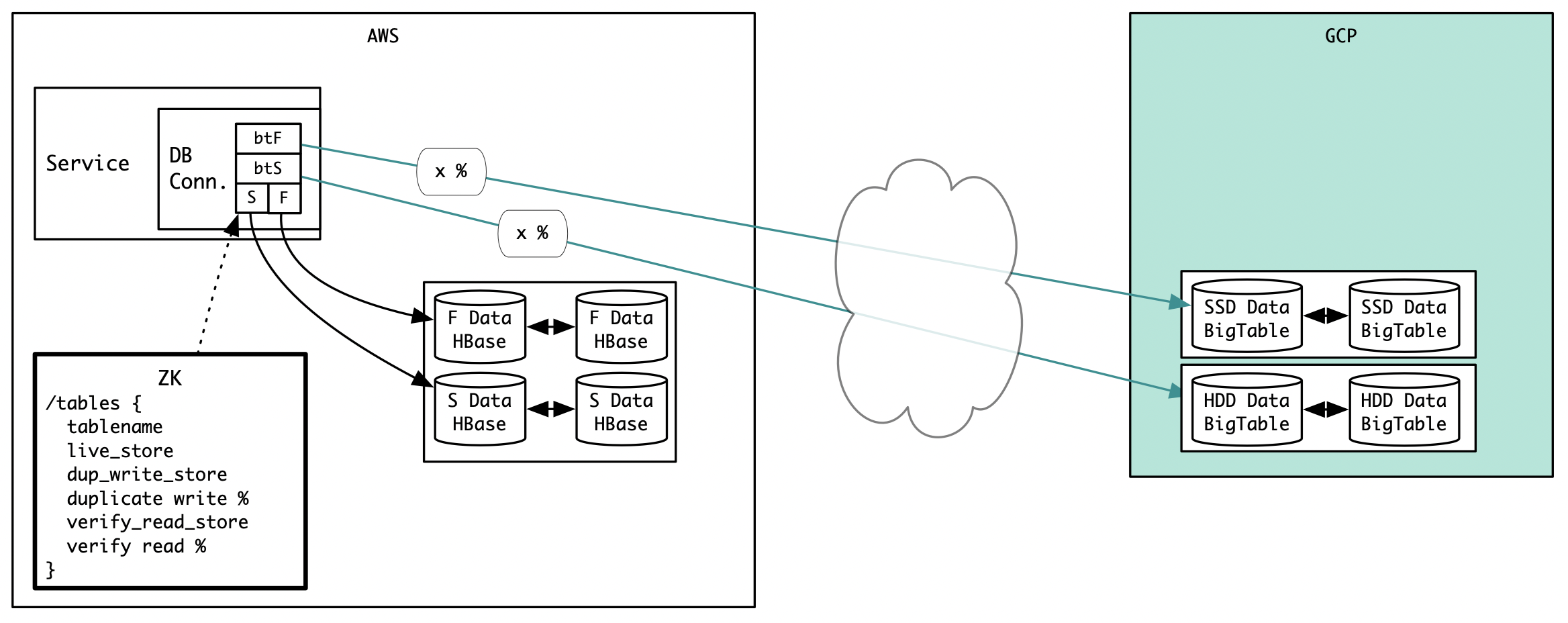
Later in this article, we will describe how we planned to use this dynamic connection module to achieve a zero downtime data migration.
Unbound scan fix
During the POC we ran into unbound Bigtable scans that negatively affected performance and increased the network throughput from Bigtable to clients running in AWS. We worked around this by adding explicit pagination in our code and/or creating an auxiliary table where appropriate.
Data changes
During the POC, it was found that a fraction of the HBase tables had at least some rows larger than the Bigtable limit. In general, these formed when table schemas had made implicit assumptions about rates or cardinalities which were violated by rare heavy-hitter keys. For instance, a programmatic use by an end user might cause a single content to have millions of updates. Since even a single such row with excessive data in a Bigtable table would cause errors while backing up the table, this had to be fixed before migration. This required us to make code and schema changes to get rid of large rows (eg: making the timestamp part of the rowkey) or migrate data to new tables with suitable schemas.
Data validation
One of the challenges with data migration is confirming that the data is the same in the source and target, i.e., HBase and Bigtable. This is a nontrivial problem because the data in the tables are constantly changing due to customer traffic, and many tables are in terabytes in size. Doing an exhaustive comparison of the tables would be costly both in terms of time and system resources.
We decided to do a combination of full real-time validation and sampled-offline validation of table data between HBase and Bigtable. This gave us a high confidence that there was no inconsistency between a Bigtable table and the corresponding HBase table.
Real-time data validation
For real-time validation, both the duplicate-write code paths and duplicate-read code paths in the DB connector module were modified to send success, failure, and read mismatch at row, column, and cell levels metrics to our OpenTSDB metrics database. We added dashboards to visualize these metrics (see below).
The metrics we generated from the DB connector module, and the metrics we get from Google Stackdriver enabled us to visualize and juxtapose various systems easily. We created a collection of dashboards that displayed the correctness of a table migration in real time (rather than writing a job comparing two large tables post migration).
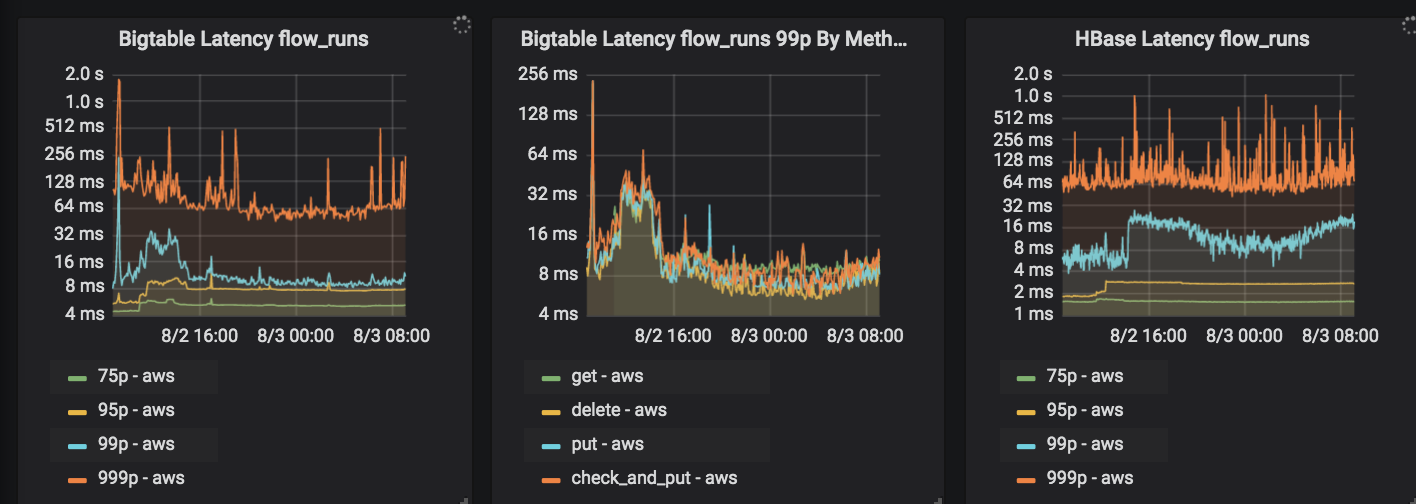
Dashboard comparing client-observed latency for a single table between HBase & Bigtable
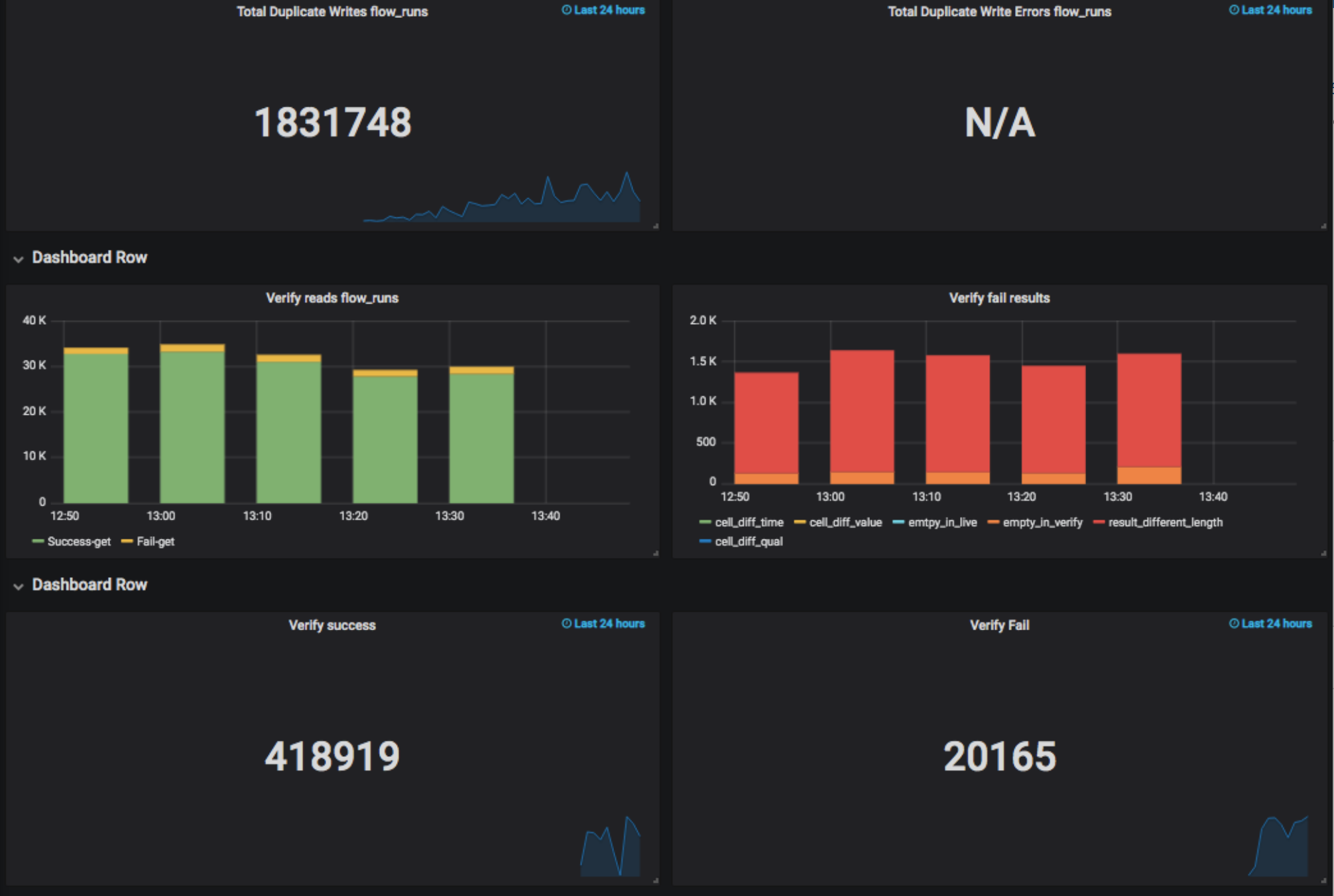
Chart showing how well the duplicate writes & verification reads were doing for a given table
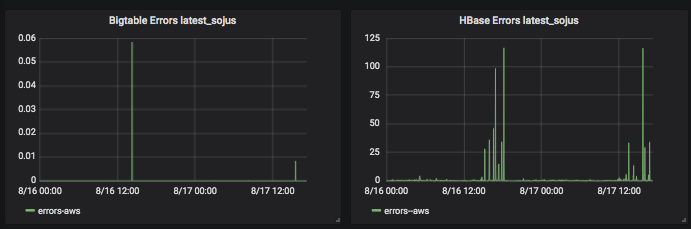
Chart showing datastore-reported errors for HBase and Bigtable for a single table
Offline validation
Since the real-time reads wouldn’t catch historic data differences, a tool was built to compare an HBase table with Bigtable table by taking a tunable number of sample rows from a tunable number of rowkey locations.
Together, these two tools gave us a high degree of confidence about data correctness and the consistency of the data in the tables between HBase and Bigtable.
Batch system changes
As described in the introduction, Sift has online and offline systems. The offline (batch) system consists of Hadoop Mapreduce and Spark jobs and an Elastic MapReduce (EMR) setup that typically use table snapshots of the live data as inputs. In order to minimize the number of moving parts during the migration, we planned to migrate the online systems (customer facing services and associated data) to Google Cloud Platform (GCP) first and the offline systems later. This meant that during the period when the offline systems remain in AWS we needed to ensure the data is made available appropriately to ensure our periodic model training and business-related batch jobs would run seamlessly.
For this, we planned a transition like this:
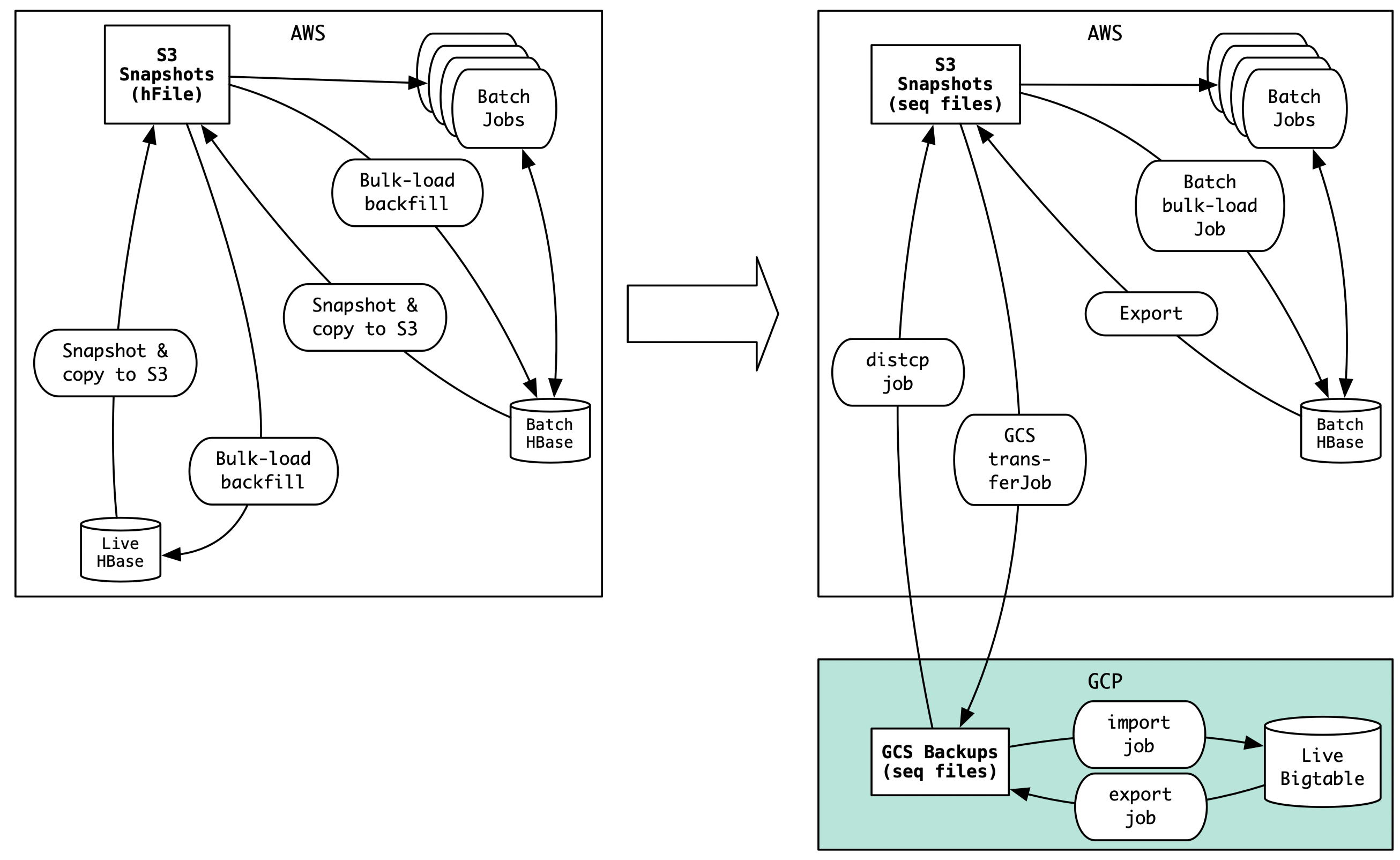
This transition required us to make a couple of significant code changes in our batch jobs:
Modifying batch jobs to handle new input format
In the HBase-only world, our batch processing pipeline ran off HBase snapshots stored in S3. The snapshots are essentially collections of files in hFile format. Whereas, the Bigtable daily snapshots are Hadoop sequence files. Therefore, we modified and re-tuned the batch jobs to use hadoop sequencefile as input instead of hFiles.
Bulk-load process changes
In HBase world, we bulk loaded data into HBase by adding hFiles directly to HDFS and then using an HBase client call to load those files in HBase. This is an efficient procedure because the hFiles are already partitioned to match HBase region servers.
During the transition period, we saw the need to bulk load data, in sequence file format, into Bigtable tables as well as the batch HBase tables.
For Bigtable bulk load, the only option was to use the Cloud Dataflow import job. We added a pipeline for this.
It was not trivial to import data in sequence file format into HBase though, because there is no region information in sequence files. To tackle this, we used a transient HBase table schema and used the information in it to distribute the sequence file data among regions as HDFS hFiles, and then used the HBase client to load the data into the destination table.
Single source of truth for datastore location
While the HBase data was being migrated to Bigtable, we were also planning to simultaneously migrate our application services to GCP (will be covered in another blog article). In order to keep a consistent view of the datastores in both AWS and GCP services, we decided to use a single copy of the Zookeeper node (that defines table -> datastore mapping, as discussed above) that will be used by services in both clouds to lookup table location. We planned to keep this Zookeeper node in AWS during the migration, and once all services have been migrated, move it to GCP.
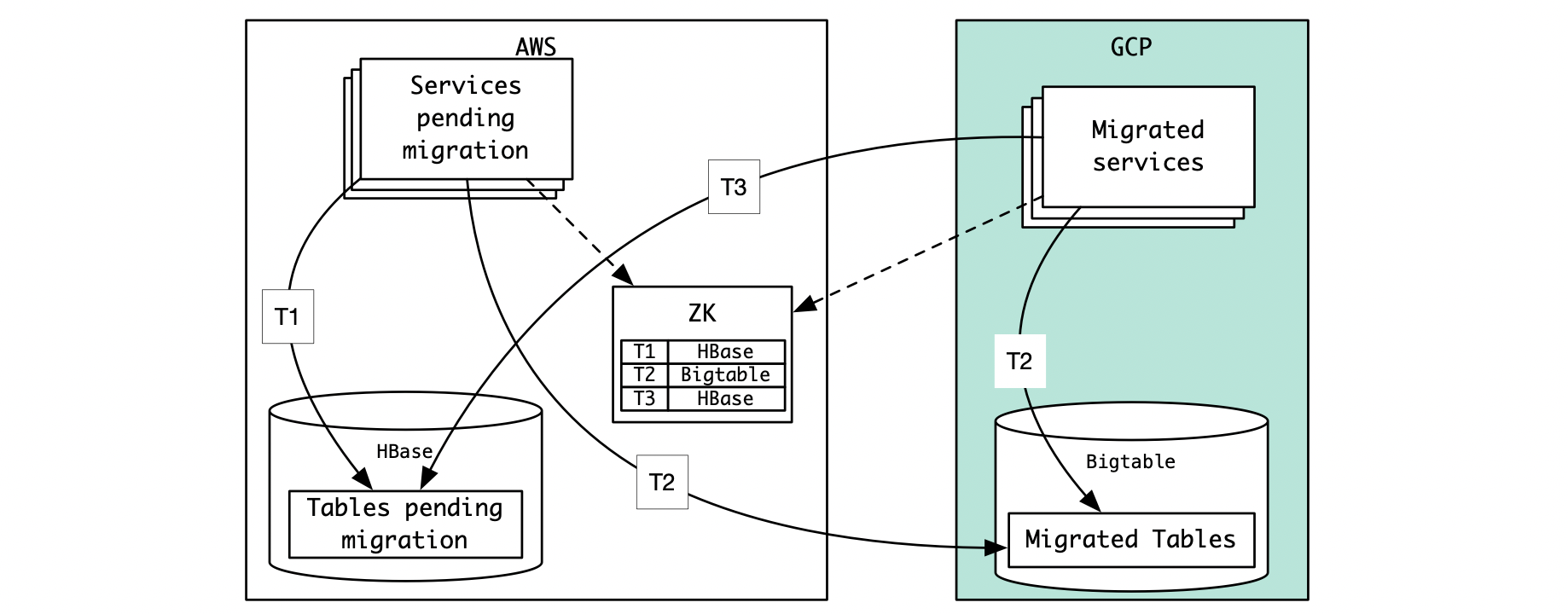
Infrastructure changes
The bidirectional cross-cloud traffic from the above setup would be costly if it went over public internet. To mitigate this, we worked with an external vendor to implement a secure and compliant cloud-interconnect that enabled us to communicate between AWS and GCP. This was about 5 times cheaper than using the public internet. It took a few iterations for us to mature this setup, and some of the interesting interconnect details will be discussed in another blog article.
Metrics HBase to Bigtable migration
One of our HBase datastore in AWS held the OpenTSDB metrics data. This data had to be moved to Bigtable in GCP as part of our migration, but we found the process to be much less complex due to the relatively straightforward use of this datastore. Therefore, while doing the preparatory work for data migration, we quickly migrated our metrics HBase into a Bigtable. We also set up our metrics reporting system to send metrics to the GCP hosted metrics Bigtable. This allowed us to take advantage of the GCP monitoring tools to observe and manage our metrics datastore.
Strategy for data continuity & zero downtime
Our team has a lot of operational experience in zero-downtime HBase replication and migration. We have built tools to create a replica HBase cluster of a live HBase that was serving traffic. We have used this replication process to upgrade the underlying EC2 instance type of a live HBase by using a replica cluster. We have also used a similar process to split the data in a single live HBase to a slow/fast tiered HBases without causing any downtime.
For the above replication, our typical steps have been to (a) create a HBase replication peer for the live HBase, (b) pause the replication on the live HBase (which would cause new edits on the live HBase to accumulate for replication), (c) take snapshots of tables on the live HBase, (d) copy over the snapshots to the peer HBase’s HDFS, (e) restore the snapshots into the target tables in peer HBase, and finally (f) un-pause replication to replay accumulated edits on live HBase to the peer HBase. This process guarantees data continuity.
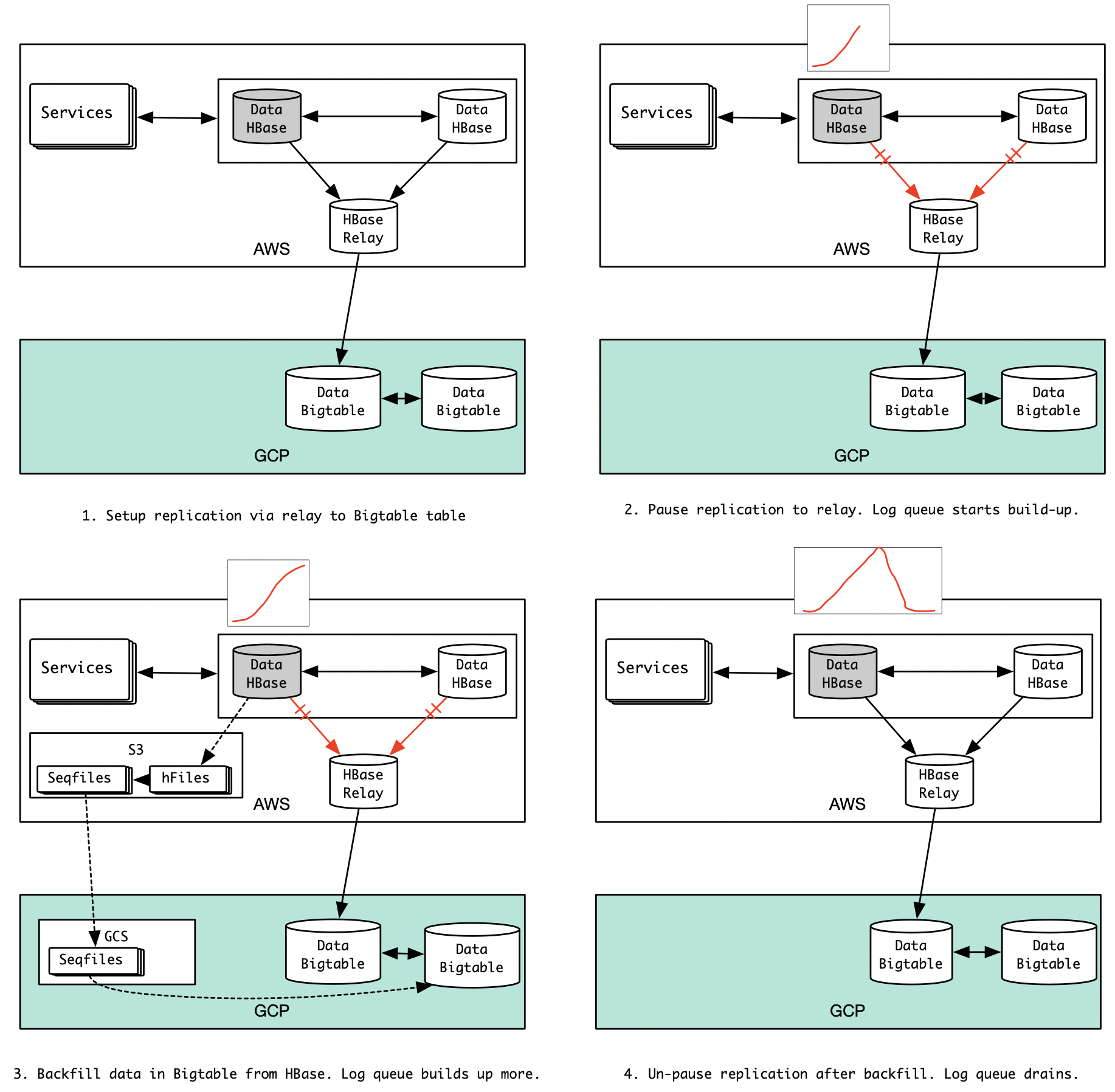
For the HBase to Bigtable migration, our initial impulse was to use a similar, familiar approach, with a relay HBase that would forward the edits to the Bigtable cluster. Let’s call this Option-A. In this approach, when we pause the replication from live HBase (in grey below) to the relay HBase, the edit log queue would start building up in the live HBase source. At this point, we will snapshot the live HBase data and import (backfill) it into Bigtable. We can unpause replication after backfill, and the log queue would drain applying queued up edits to Bigtable via the relay. Since we could have a HBase failover at anytime during this process, we would need to set this up in a triangular manner, as shown below. The sequence of steps for Option-A is shown below:
A different approach (let’s call it Option-B) could be to do 100% write mirroring of live HBase writes for a table to Bigtable, and then take a snapshot of the table on live HBase, create sequence files off it, and import them into Bigtable. Once data validation succeeds for this table, we would make Bigtable the live store and HBase the mirror store for this table. If we see performance issues for this table, we can rollback to HBase as live for this table without losing data because we would be mirroring Bigtable edits to the corresponding HBase table at this point. This sequence would look like the following:
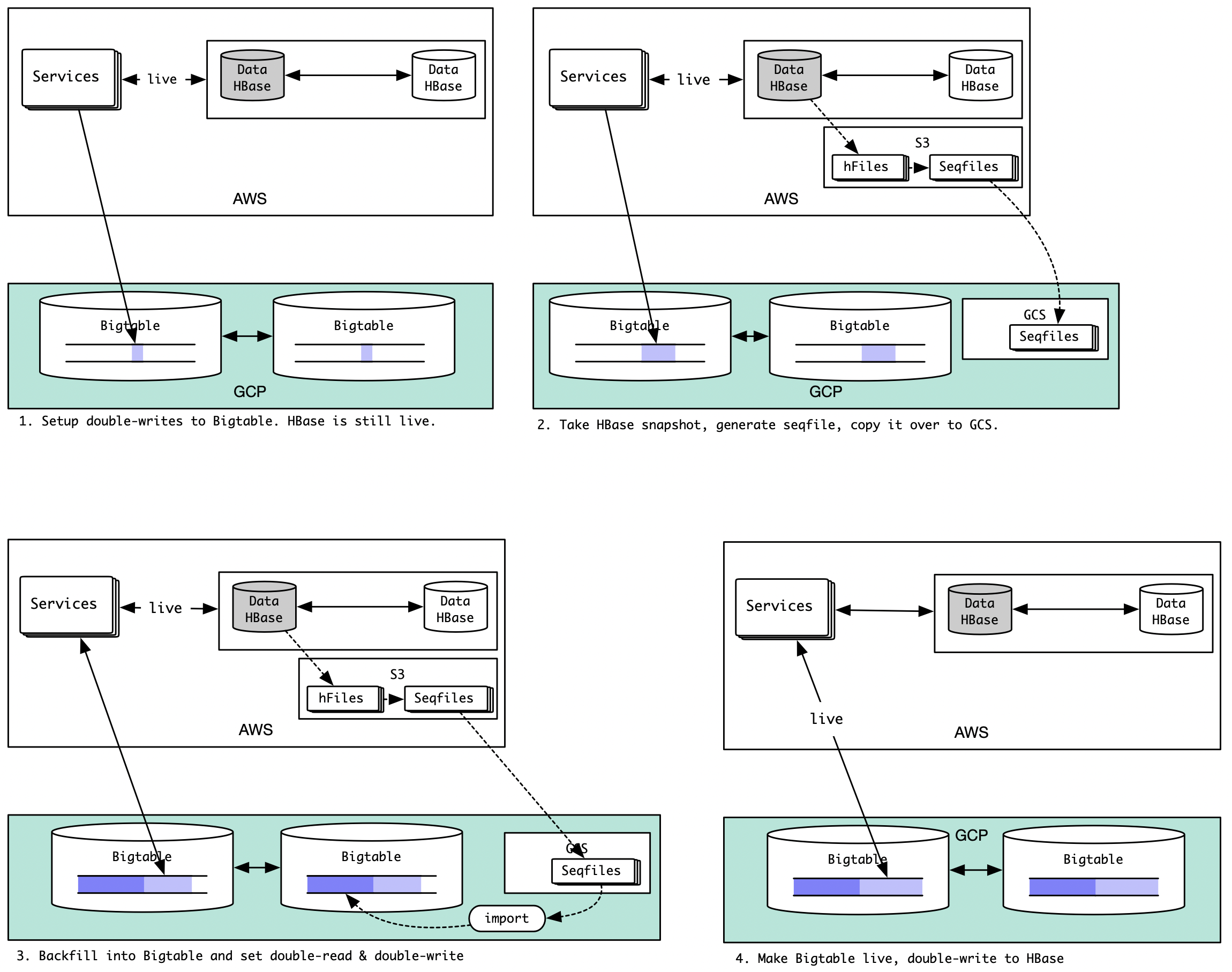
One caveat with Option-B would be the small overlapping window of writes. This may or may not be okay depending on the use case.
From past records, we realized that Option-A would be very complex. Replicating from multiple sources would put a lot of memory and network pressure on the sink (HBase relay). Moreover, for the “pause replication, copy over snapshot data, and replay edits” to work, the “copy over data” step needed to work fairly quickly. Unfortunately, the “copy over data” step has 3 sub-steps (export from snapshot hFiles to sequencefiles, transfer from S3 to GCS, and import to Bigtable table), which took more than 2 days for some large tables. Accumulating edits for days (this would need a lot of extra storage on HDFS) and replaying it (this would probably take another day or two) didn’t seem like a robust process.
Zero downtime for our customers was our #1 priority. Therefore we needed to be able to switch back to HBase if we observed performance degradation or verify mismatches upon switching to Bigtable. A prerequisite for this was bidirectional replication. Unfortunately, it is nearly impossible to get the Bigtable -> HBase replication in Option-A.
A closer analysis on our 100+ tables (a tedious exercise, considering legacy data and processes) showed that the overlapping window of edits in Option-B would not cause any correctness issue for us. This option also allowed us to do bidirectional replication, allowing zero disruption for our customers. Therefore we decided to go with Option-B.
Overall migration plan

Once our code changes and observability tools were in place, it was straightforward for us to plan the data migration. We grouped the tables to be migrated into batches. Tables with schema/data changes to be done (due to large rows) were to be migrated last. Tables with high data throughput were also marked to be migrated later in the timeline to plan for the cloud-interconnect to be ready by then.
In general, our migration strategy for the tables fell into three categories:
- If the table is static in nature, then simply copy the data over to the Bigtable table.
- If the table has transient data (low TTL), then create an empty table in Bigtable.
- For other tables, do double-writes and backfill. Majority of our tables fell into this type. The plan was to ramp up double-writes to the Bigtable table to 100%, then take a snapshot of HBase table, create sequence files from snapshot, copy them over to GCS, import them to the Bigtable table getting double-writes but on the secondary cluster, and verify correctness with the help of the online & offline data validation tools. If all is well with a table, setup daily backups of the table in Bigtable.
The steps in the third category could be a multi-day process for some tables, but most of it was automated, so one could start it with a single command. These steps are also retry-able: if we noticed verification issues or performance issues with a table at any point, we could easily rollback, re-backfill and re-verify.
What is next?
In this article, we described how we went about laying the groundwork for the zero downtime data migration.
In the next article of the data migration series, we will share some lessons we learned from the data migration journey.