Migrating our cloud infrastructure to Google Cloud
(Part 1/4)
At Sift, we have built a scalable and highly available technology platform to enhance trust and safety in the digital world. We ingest, process, and store petabytes of data from our customers from around the globe. When our customers query us about the fraudulent nature of an online event on their systems, we respond to them in real time in the form of a trust score of that event.
We recently migrated our cloud infrastructure from Amazon Web Services (AWS) to the Google Cloud Platform (GCP) to meet our growing business needs, and we would like to share our migration experience with the engineering community.
The target audience of this four-part series (part-2, part-3, part-4) is technology enthusiasts and engineering teams looking to do similar cross cloud migrations.

Our system in 2018
The Sift platform was hosted in the AWS cloud, powered by Java web applications. We used Apache HBase as our main datastore, primarily for its strong consistency model and its tight coupling with the Apache Hadoop/Map-Reduce ecosystem. We provisioned and hosted HBase ourselves on Amazon Elastic Compute Cloud (EC2) instances. Over the years, we also built numerous tools to manage HBase (merge, split, and compact regions, do cluster replication, snapshot, backup, backfill, monitor, and failover). In addition to HBase, we had other smaller datastores like Elasticsearch, Amazon RDS, MongoDB, and so on, all hosted in AWS, and performing critical tasks within the Sift platform. A simplified view of Sift’s online and offline systems looked like this in 2018:
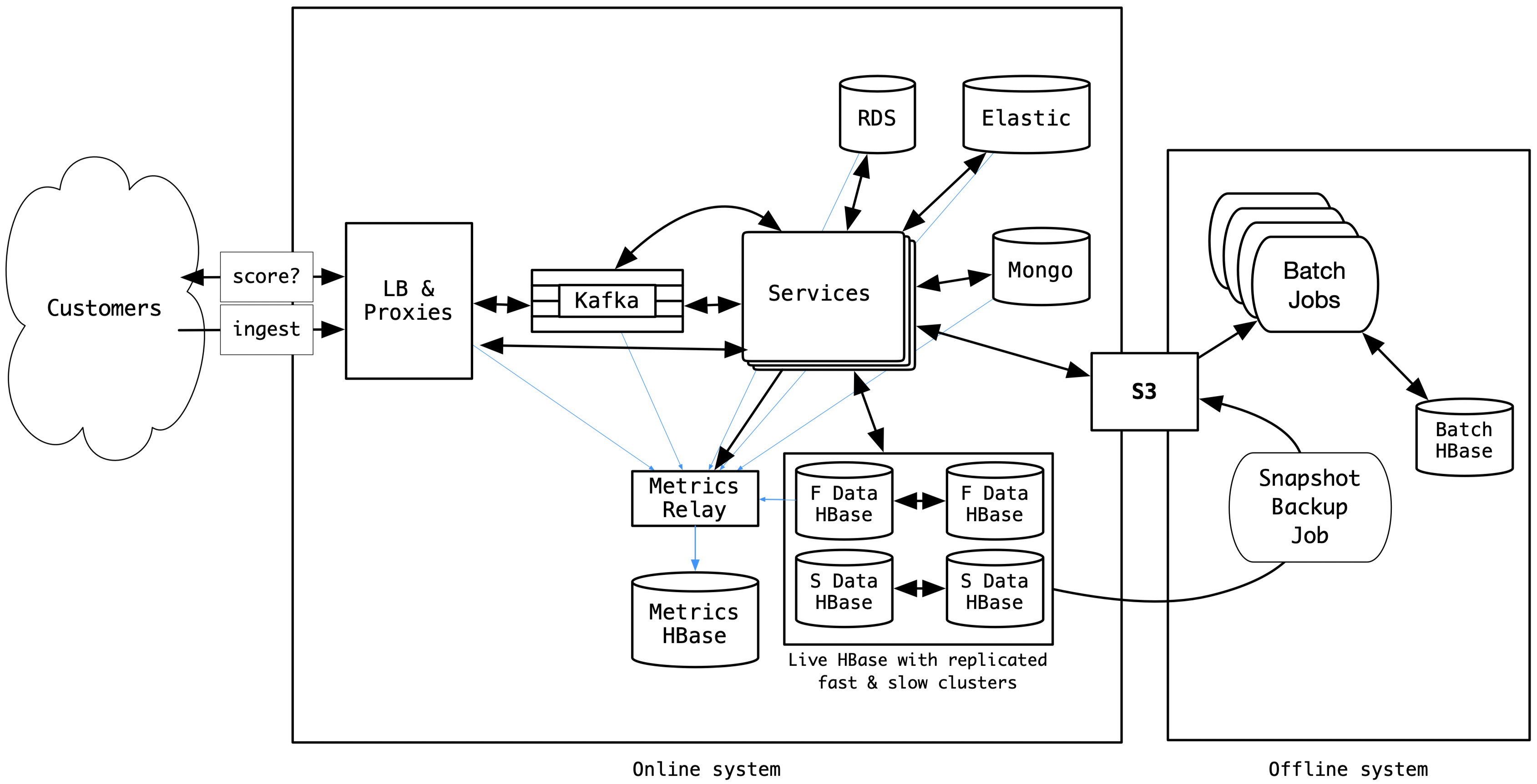 Sift uses multiple machine learning models to identify different kinds of fraud. We have a complex and thorough batch-training process that looks at historical data to build the models periodically. In addition to the model training process, we also have a collection of batch jobs for reporting, billing, experimenting, and so on. These batch jobs are mainly map-reduce jobs, and are I/O intensive. In order to avoid hitting the live HBase (which was also serving the online system, as shown above), we took daily snapshots of HBase tables and copied the snapshot hFiles to S3 in an incremental manner. The long-running, I/O intensive batch jobs were set up to use the snapshot hFiles in Amazon’s Simple Storage Service (S3) as input. The S3 snapshots also served as disaster-recovery backups. A small subset of live tables were also made available in a separate batch HBase cluster in order for some batch jobs to use a consistent execution path in shared modules. These form the offline system, as shown above.
Sift uses multiple machine learning models to identify different kinds of fraud. We have a complex and thorough batch-training process that looks at historical data to build the models periodically. In addition to the model training process, we also have a collection of batch jobs for reporting, billing, experimenting, and so on. These batch jobs are mainly map-reduce jobs, and are I/O intensive. In order to avoid hitting the live HBase (which was also serving the online system, as shown above), we took daily snapshots of HBase tables and copied the snapshot hFiles to S3 in an incremental manner. The long-running, I/O intensive batch jobs were set up to use the snapshot hFiles in Amazon’s Simple Storage Service (S3) as input. The S3 snapshots also served as disaster-recovery backups. A small subset of live tables were also made available in a separate batch HBase cluster in order for some batch jobs to use a consistent execution path in shared modules. These form the offline system, as shown above.
The challenges
With the growth of our business, the amount of data we stored in HBase crept close to a petabyte by 2018 and kept growing. With this, we started to encounter a number of operational and performance bottlenecks, and subsequently, challenges around the stability of HBase.

Hardware issues
Whenever there is an EC2 instance retirement (due to hardware failure or maintenance in AWS) in the HBase fleet, the regions served by the retired instance get moved to another instance. This recovery process is built into HBase. But during this recovery, our application clients that used HBase usually experienced elevated latencies. The EC2 retirements became more common as our HBase fleet got close to 1000 EC2 instances. This resulted in occasionally elevated client latencies that affected customer experience. This was not acceptable when we strive to provide a 24×7 low-latency service to our customers.
We had a hot standby HBase replica for high availability. While the EC2 instance retirements in the active HBase hit client performance, such retirements in standby HBase caused excessive build-up of replication logs in the active HBase. The replication log build-up often took many hours to drain, during which time we could not safely failover to the replica.
The failover process itself was delicate; we had to manually ensure that the standby was in a good state before failing over. Often times the EC2 instance retirements happened at night, and performing failover manually was a high-stress operation for the on-call engineer. To mitigate this, we automated the failover process in Summer 2018 by observing a number of signals. But this still meant time-sensitive follow-up actions from engineers.
Not catching up with the churn
In order to provide highly available, low-latency service to our customers, we chose to run our own lightweight compaction instead of HBase major compaction. It was challenging for us to maintain our own compaction due to our table sizes growing at a fast pace with the business growth we were seeing. Meanwhile, HBase minor compaction was adding files to the archive directory for our high throughput, low TTL tables faster than HBase archive cleaner chore could keep up. This resulted in needless growth in storage utilization.
Balancing HDFS storage utilization among the datanodes also became challenging because there was a tradeoff between aggressive rebalancing and live traffic performance due to limited network capacity.
Delaying batch jobs
As some of our tables got close to tens of thousands of regions, it frequently took more than a couple of hours to snapshot a table and copy the snapshot to S3. Since our daily batch jobs relied on the S3 snapshots, such delays affected some of our batch operations. We had alerts to catch such delays and this also added on to the on-call toil.
High risk operations
These were very rare, but we ran into a couple of HBase master deadlocks as the amount of data and regions grew. When this happened, we failed over to the healthy HBase and, on the deadlocked HBase, performed the surgical operations like clearing “regions in transition” entries in the ZooKeeper or fixing entries in the Postgres table where Cloudera Manager saved HBase master states. Any mistake in such undocumented operations would have made the HBase cluster unusable. Even though time consuming, we successfully recovered from HBase master deadlocks without affecting any of our customers. However, this operational overhead was not sustainable for us.
Impact on productivity
In order to meet our stringent customer SLAs, we were incurring a large operational cost to ensure these HBase issues were not impacting our services.
By Fall 2018, we were experiencing about 25 HBase incidents a week. Managing HBase on our own had become unsustainable at this point.
Cost
Our deployment of HBase was backed by HDFS running with 3x replication for high availability. As our data grew, with the business growth, we started to feel the storage cost of these replicas. For high availability, we had set up HBase replicas in different AWS availability zones (AZs), and HDFS block placement also in different AZs. The cost of data transfer between the different AZs for this setup compounded the problem.
The opportunity
The pain of self-managing HBase prompted us to explore datastore alternatives. We considered breaking HBase into many smaller tiers, but the cost and operational overheads did not make sense to us. We also considered DynamoDB and other datastores, but a new data model would mean a lot of code changes to our existing fleet of application services and this was a non-trivial effort. The new cloud offering from Google, the Cloud Bigtable was appealing partly because of the API compatibility with HBase (after all, HBase was the open source incarnation of the Bigtable paper), which meant that most of our application code didn’t have to change if we switched to use Bigtable. It was also assuring that Bigtable was a battle-hardened system inside Google, and a reputed technology provider like Google was offering it as a managed service.
The lion’s share of our infrastructure expenses and operational overhead came from running HBase. Therefore, we saw that a migration of our datastore to Cloud Bigtable could take with itself our entire cloud infrastructure to the Google cloud. Such a move would simplify the operational complexity of maintaining systems in two clouds and also the cost of inter-cloud data transfer.
What is next?
Now that we have presented our rationale for exploring Google Cloud, we will be presenting our experiences in the following series of articles.
- Evaluation of Bigtable: while the Cloud Bigtable sounded appealing in theory, let us ensure that it met the throughput, performance, adaptability, and reliability requirements of Sift.
- Planning the zero-downtime data migration: let’s ensure there is zero customer impact during a migration.
- Lessons learned from data migration: key takeaways and lessons learned during this journey.