Watchtower: Automated Anomaly Detection at Scale
As the leader in Digital Trust & Safety and a pioneer in using machine learning to fight fraud, we regularly deploy new machine learning models into production. Our customers use the scores generated by our machine learning models to decide whether to accept, block, or watch events like transactions, e.g., blocking all events with a score over 90. It’s very important that our model releases don’t cause a shift in score distributions. Score shift can cause customers to suddenly start blocking legitimate transactions and accepting fraudulent ones. In early 2019, we realized a model release could pass our internal automated tests but still cause a customer’s block or acceptance rate to increase. The Engineering team started brainstorming – what were the conditions under which this could happen? How could we prevent it? We started to understand that we should investigate automation of model releases to reduce human error.
As our business continues to grow, we can’t rely on humans to check every customer’s traffic pattern. We needed a scalable tool for monitoring customer outcomes in real time, knowing that each customer has unique traffic patterns and risk tolerances.
The Challenge
Our customers have built thousands of automated workflows using score thresholds to make automated block, accept, and watch decisions. Even a slight change in the score distributions may impact decision rates. Tuning these automated workflows to the right score threshold is very important as they can affect customers’ business, either by blocking legitimate transactions and losing profit, or accepting fraudulent transactions which results in financial or reputational losses.
These anomalies in decision rates can be caused by internal changes in models and system components. They can also be caused by changes on the customers’ side: a change in integration, or decisioning behavior. Sometimes a change in decision rates is desirable – such as when there’s a fraud attack, entering into a new market, or a seasonal event.
The most important thing is to identify and triage changes in decision rates immediately in an automated way to ensure that customers continue to get accurate results with Sift.
The Solution
The solution had to meet the following requirements:
- Accurately identify anomalies per customer level
- Automated alerts
- High availability
- Help triage the extent and impact of the anomaly
- Support initial root cause analysis
Because each customer has unique traffic and decision patterns, we needed a tool, which can automatically learn what “normal” looks like for each customer.
We built an automated monitoring tool, Watchtower, a system that uses anomaly detection algorithms to learn from past data and alert on unusual changes. In its first version, it allows us to monitor and automatically detect anomalies in decision rates we are providing to customers. It is easily extensible to other types of internal and external data to help us detect unusual events.
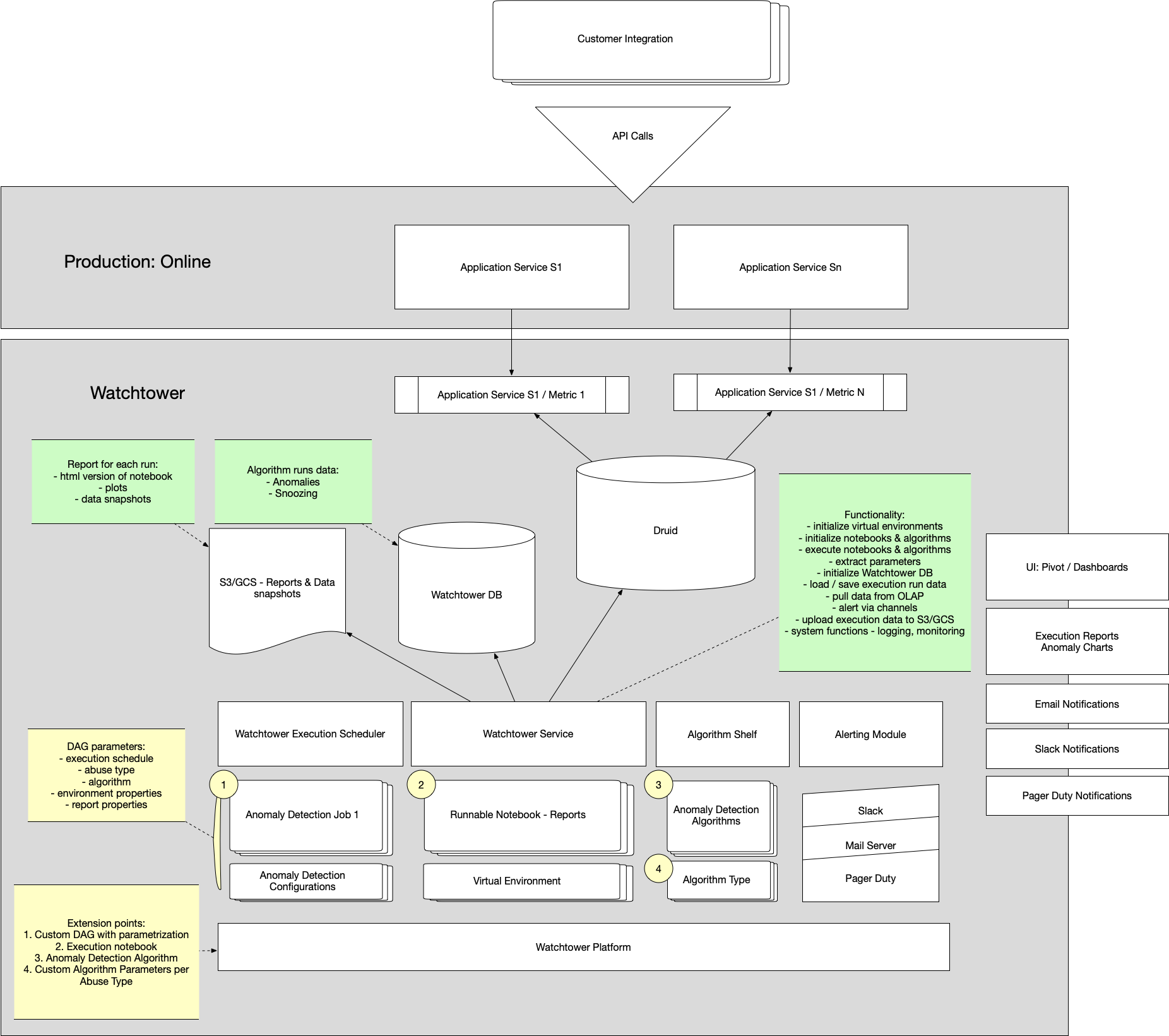
Architecture
Watchtower architecture has 4 categories of components as shown in the diagram below.
Scalable tooling for streaming data collection
We’ve built a portable library with a simple API. It can be used to intercept requests to service, reformat and send data to a distributed messaging system. We use Kafka because of its scalability and fault tolerant characteristics.
Data storage for aggregating and querying streaming data in near real time
We need to aggregate data by a variety of dimensions from thousands of servers. We need to query across a moving time window with on-demand analysis and visualization. For this, we use Druid, which in our case proved to be a good choice as a near-real-time OLAP engine.
Services that ingest aggregated time-series data, run the anomaly detection algorithm, and generate reports
We need a service that can fit the following requirements:
- Run jupyter notebooks with dependencies in virtual environments. Notebooks are written by data scientists and machine learning (ML) engineers.
- Pull and cache time series data.
- Configurable to support multiple products with a variety of unique requirements – such as algorithms, whitelisted customers, benchmark data, etc.
- This was a key weakness in many external solutions we looked at.
- Alert via configurable channels such as Slack, emails, PagerDuty.
- Support alert snoozing to prevent repeated alerts.
- Store input time-series data which was used during execution for future investigations and algorithm tuning.
In order to satisfy these requirements, we’ve built an in-house solution. These services support a variety of configurations and schedules. The results of service runs are stored in PostgreSQL. Artifacts of the run are stored in S3 & GCS, which include input data snapshots and outputs of the jupyter notebooks executions in HTML format.
Tooling for Offline Training, Modeling, and Benchmarking Algorithms
The algorithm must learn from unlabeled data, but we want to evaluate it against known historical anomalies. This helps us tune the sensitivity parameters of our algorithms, and provides context for support engineers. To do this, we’ve built tools to join data from multiple data sources and run backtesting on algorithms. Once the algorithm is tuned, it can be deployed into the model shelf.
User Interface
We use plots generated by anomaly detection notebooks for alerting via various channels. Each alert contains the name of the customer with anomaly in their decision pattern, the metric which triggered the alert, and a link to a dashboard which updates in real time.
Dashboards allow us to slice and filter data per decision type, product type, time of the day, etc. We monitor statistics on decisions and score distributions.
Here’s an example of a dashboard for one of Sift’s internal test customers presented below.

The Impact
From a business standpoint, Watchtower far exceeded our expectations. In the first month of launch, we were able to detect several possible anomalies without human intervention. We analyzed the data and saw a variety of root causes such as:
- Incorrect integration changes with Sift REST API on one of the customers side
- A mis-calibrated model for one of our customers before we released the model
- Severe fraud attack on one of our customers
- Spikes related to expected change of patterns such as promotion event ad campaigns
With Watchtower, our support engineering team was able to proactively contact customers quickly when anomalies were spotted, which prevented any potential business impact for our customers.
Summary and Next Steps
Overall, Watchtower exceeded expectations by automating the anomaly detection in our customer traffic and decision patterns for expected and/or unexpected reasons. Our next steps will be focused on adoption of new use cases as well as improving anomaly detection algorithm performance.
We plan to use Watchtower for new types of data besides the decisions, both in business and engineering. For example, we plan to use it to monitor score distributions and system loads.
For the algorithm part, we have started testing a number of promising deep neural network algorithms, including variations of LSTM and CNN.
Finally, we want to make Watchtower a self-serve service , where engineers without machine learning and data science backgrounds can use Watchtower for anomaly detection in any type of application.
Want to learn more or help us build the next generation of anomaly detection? Apply for a job at Sift!