Sift Engineering Holds Spring Hackathon
This spring, Sift Science Engineering completed another one-week hackathon. Sift has a long tradition of hackathons and many hackathon projects have turned into successful products, such as our Account Takeover product and our use of Deep Learning.
The rules of Hackathon are simple — you must do something that is somehow beneficial to the company, and you have to be ready to give a demo by the end of the week. That’s it. Engineers can work solo, or in groups. Asking people to take a week to pursue whichever ideas they choose generates a lot of creativity that can’t be replicated with top-down planning.
Hackathon projects ranged across the board, from streaming technologies to containerization to speeding up offline pipelines to ML clustering techniques to deployment frameworks. Overall, there were 22 different hackathon projects. Going into all of them would take far too long, so we’ll stick to covering those projects voted as best in several categories by the whole company.
Most Excited
Following the launch of major improvements to our Content Abuse product, a number of groups focused on new machine learning techniques for identifying fraudulent content — whether that’s a dodgy classified ad, a fake dating profile or plain old spammy comments. One of these was voted the project that Sifties were Most Excited about. The trio of Sam Ziegler, Reggy Long and Kuba Karpierz proposed a method of using Locality Sensitive Hashing over document vectors to spot content similar to known bad content. Once a piece of content is identified as bad (which can mean scams, spam or any manner of harmful) then this method can help identify content that is similar but not the same. For example, if “send me your resume via my Email address” is marked bad, this can identify “Send your resume or your availability to my email address” as similar. Additionally, they experimented with using latent Dirichlet allocation to categorize and group texts, again helping to identify potentially problematic content that is similar to known bad content. Thus leveraging both supervised and unsupervised machine learning, they offered new ideas for stopping more bad content on our customers’ sites.

Reggy, Sam and Kuba, seen here categorizing content the old-fashioned way
Most Impactful to Sift’s Future
As Sift grows, we take on more customers and with them grow our data volume. There is a constant need to re-evaluate architectural choices that will allow us to scale 10x, 20x and beyond. Michael Parkin and Scott Wilson spent their hackathon investigating the use of Google Cloud Platform’s Bigtable vs our existing HBase functionality. One of the challenges with moving a critically important data store is the requirement for zero-downtime during the migration. How could we perform a migration from HBase to Bigtable and maintain constant availability during the process? Michael and Scott explored migration methods that involved rewriting HBase’s replication framework to populate a Bigtable instance over time so that they would eventually reach parity, allowing for a changeover without taking any downtime on production services. They additionally wanted to test the latency involved in using SQL databases across two different data centers, and provided performance numbers at a median, 99p and 99.9p level. The results of their work were very interesting, and will continue to be discussed as Sift grows and scales to new heights.
Most Helpful To My Work
MapReduce is a bread-and-butter tool at Sift. To help make everyone more effective, Micah Wylde and Jacob Burnim took on the task of improving our platform and best practices to speed up MapReduce jobs across the board, in some cases up to 10x. They attacked this problem in a number of ways. Previously, any job that needs to get all of the values for a particular key would need to run an initial and expensive shuffle/reduce step to merge all key/value pairs for the same key together from multiple HFiles. However, they had the insight that HFiles are already sorted by key and grouped into regions, so rather than sort everything, they can merge them together. They developed a new streaming HFile input format that uses a k-ways merge sort to merge cells with the same key. Additionally, they noticed that jobs were often slowed down when there were several very small HFiles that added the unnecessary overhead of spinning up an extra map task per HFile. By changing our input methods to merge together small HFiles, they saved significant time. By doing some careful reasoning into how we can do less and do it better, their performance improvements will reap ongoing benefits and allow Sift to keep moving faster to experiment with new ideas.
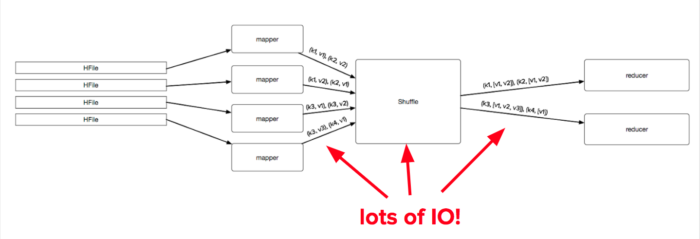
Before: joining multiple values for the same key required sorting and reducing.
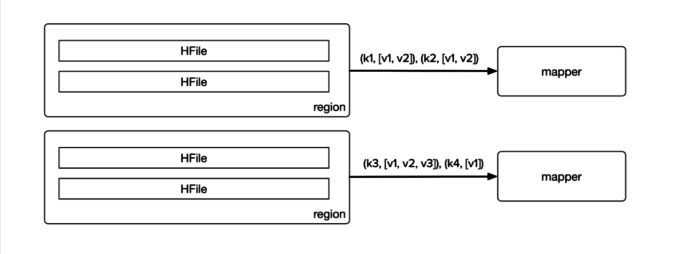
After: HFiles per region are merged before the first map cycle begins.
Best Presentation
Leave it to the frontend magicians of Noah Grant and Zorah Fung to win the Best Presentation award. Noah and Zorah worked on a beautiful Component Library for Sift’s console codebase that documents and displays the various components that form the foundation of our console. It runs as a Gulp task and automatically pulls from comments and metadata present in the component code. Additionally, it provides an interactive sandbox for editing the examples to see how they can be changed. This can be used as a reference not just for frontend developers but also for product designers when designing new products. It took about 3 seconds after the presentation for designers and product managers to shower them with congratulations and praise!
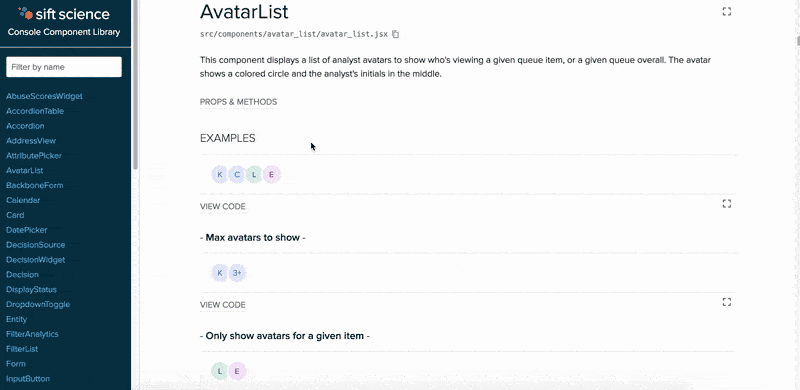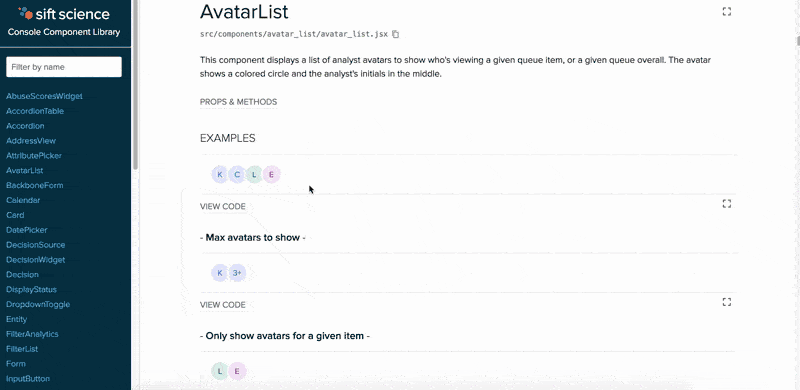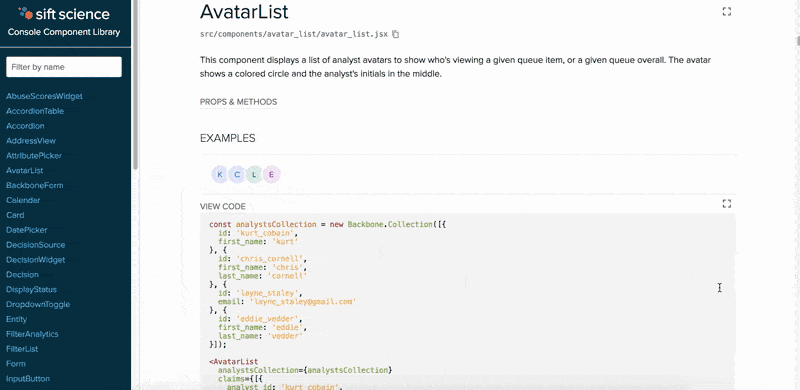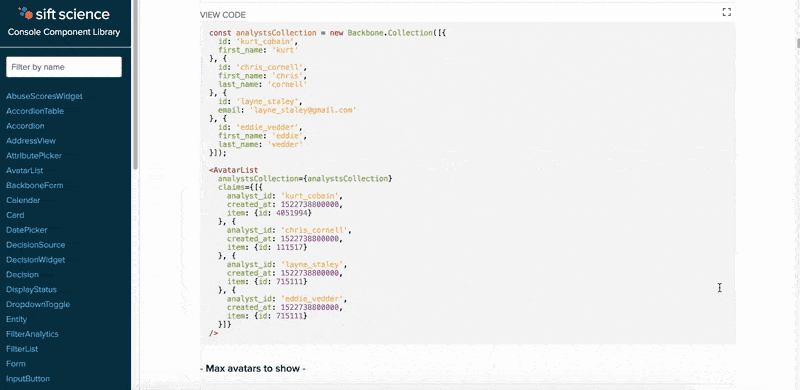
The Component Library in action
Thanks to our Seattle team for a little extra 90s grunge!
What You Want Sift To Prioritize
Machine Learning isn’t just about accuracy, but about what customers need. Vera Dadok went beyond traditional accuracy measures to think more about what actually moves the needle for our customers who use our system to fight fraud. In particular, she developed a measure of accuracy that was weighted by the financial value of a transaction, rather than just whether or not it was fraudulent. She then showed that in some situations, different models perform better when measured on weighted accuracy. For example, in one instance, a ensemble model performs better in terms of AUC-ROC, but when evaluated with value-weighted labels, one of the component models performs better. There are several more avenues to explore in this area to better align our model training criteria around what will provide the most benefit to customers. Being always customer-focused, Sifties voted this as what they most wanted Sift to prioritize, so there may be more on this soon…

Vera: “Show me the (possibly fraudulent) money!”
Of course, there are many other interesting projects that this post does not highlight. We’re looking forward with excitement for the next hackathon later this summer, featuring our fantastic summer interns!
If any of these projects interest you and you’d love to work in an environment where the hackathons and the daily projects are filled with challenging, interesting work, then check out our careers page!