Large Scale Decision Forests: Lessons Learned

Background of modeling at Sift:
We at Sift Science provide fraud detection for hundreds of customers spanning many industries and use cases. To do this, we have devised a specialized modeling stack that is able to adapt to individual customers while simultaneously delivering a great out-of-box experience for new customers, achieved by mixing the output from a “global” model – trained on our entire network of data – with the output from a customer’s individualized model.
Prior to decision forests, we used a custom-built logistic regression classifier combined with highly specialized feature engineering for our global model. While logistic regression has many great attributes, it is fundamentally limited by its inability to model non-linear interactions between features. At Sift, we tend to think of our modeling stack primarily as an enabler of our feature engineering; more powerful modeling allows us to extract the most insight from our features and can even lead to new classes of features. So when in early 2015 we stopped seeing benefits from feature engineering work, it was clear to us that we needed a major upgrade to our modeling stack.
Motivation for decision forests:
Around January, we began investigating potential improvements to our modeling stack, and quickly identified our global model and its linear modeling constraints as the best place to start. We wanted our global model to be expressive enough to easily model non-linearities in our feature space, but we also needed to retain the ability to explain our global model’s predictions to our customers in a straightforward manner. Additionally, we needed to be able to scale up training of this new model to our very large data set without significantly increasing server costs.
Given these constraints, random decision forests seemed a natural fit. They have the ability to model arbitrary interactions amongst features, are relatively inexpensive to train, and are one of the most interpretable machine learning models around (especially when compared with neural networks, another option we considered). Beyond that, decision forests have been shown to be among the most accurate models on datasets closest to ours, and are widely used in large scale applications. Some of the other benefits of decision forests that we liked for our application include the ability to easily incorporate domain knowledge and the fact that a decision forest can be thought of as a large system of automatically learned rules. This last point is helpful when explaining machine learning to new customers who have only used rule-based fraud detection systems in the past.
Once we were sold on decision forests as the future of modeling at Sift, we set to work building out our own in-house version. We had a host of reasons for building our own implementation rather than using an existing open source implementation, but the most important was to allow us to extend and specialize the model to fit our unique dataset and feature space (as we’ll demonstrate below).
Lessons learned:
Fast forward several months and 100+ experiments later, we now have a global decision forest model working as a productive member of our modeling stack. Along the way to shipping our decision forest model we learned quite a few things about working with decision forests for the fraud detection use case. The most interesting lessons we’ve learned are detailed below:
1. Handling sparse features
A fundamental challenge with decision forest training is getting the feature vector down to a reasonably small size. In our experience, “reasonably small” means less than 1,000 features; adding features beyond that mark, even if they are individually useful, resulted in degraded accuracy in our system.
This requirement poses a problem for how sparse features are treated. At Sift, we define sparse features as any that can take on several hundred unique values (e.g. an email address). The way we handle sparse feature for our logistic regression model turns every sparse feature into tens of indicator features, which results in a feature vector with several thousand features. Given the above, we clearly needed to develop an alternate method of handling sparse features.
The approach we settled on involves turning every sparse feature into a numeric “fraud rate” feature equal to the average class prediction of all samples with the same value for said feature. This approach is best explained by a simple example:
 Let’s say a feature vector comes in with a value of “94105” for the feature “Shipping zipcode”. The first thing we do is look up (in our densification tables in HBase) the number of fraudsters and normal users we have previously seen with this shipping zipcode. If we have seen this shipping zipcode in either capacity before, we can then produce a fraud rate feature that equals the ratio of fraudsters to all users with the same shipping zipcode. This simplification results in optimal splits for at least the root node in a tree, since it directly optimizes the distribution of predictions over the leaf nodes, which is in turn the input into our split quality measure. At lower levels of a tree, this approach can result in missed opportunities to combine sparse features compared with treating every feature value distinctly, but we’ve found experimentally that this is a worthwhile tradeoff in most cases.
Let’s say a feature vector comes in with a value of “94105” for the feature “Shipping zipcode”. The first thing we do is look up (in our densification tables in HBase) the number of fraudsters and normal users we have previously seen with this shipping zipcode. If we have seen this shipping zipcode in either capacity before, we can then produce a fraud rate feature that equals the ratio of fraudsters to all users with the same shipping zipcode. This simplification results in optimal splits for at least the root node in a tree, since it directly optimizes the distribution of predictions over the leaf nodes, which is in turn the input into our split quality measure. At lower levels of a tree, this approach can result in missed opportunities to combine sparse features compared with treating every feature value distinctly, but we’ve found experimentally that this is a worthwhile tradeoff in most cases.
If a not-previously-seen shipping zipcode comes in, we will leave the shipping zipcode feature empty; that is, the feature will be missing from the feature vector. Which leads to our next lesson…
2. Dealing with missing features
Dealing with missing features in a decision forest model is also tricky to get right. Typical approaches include filling in a missing feature with that feature’s mean, median, or some default value. In our experience, these approaches erase valuable information from the feature vector; at least in our data model, the fact that a feature is missing is an important signal. This is due in large part to the flexible manner in which we allow our customers to integrate with us. For example, some customers may make the shipping zipcode field optional on their checkout forms. Whether or not the end user chooses to fill in this field is a useful piece of information for fraud detection.
So now we turn to finding a method of capturing the missing feature information and presenting it to the decision forest model. The need to keep the feature space small eliminates the approach of creating a “feature XYZ is missing” indicator feature for every feature we emit. Instead of expanding the feature vector, we modify the decision forest model itself by adding a third “missing feature” branch to every interior node:

This third branch is traversed whenever the feature vector we are examining is missing the feature an interior node is split upon. The beauty of this approach is three-fold:
- The model is now more expressive and easier to interpret since it takes the guesswork out of which branch a sample will traverse if it is missing a feature.
- Accuracy is significantly improved thanks to the increased modeling capacity and the the model’s ability to learn distinct sub-trees for samples without a given feature.
- Training time isn’t affected since the sufficient statistics required to compute split impurities given this third branch are already collected as part of our regular training algorithm.
3. Training optimizations
We learned a number of things about training a decision forest model while tuning our training algorithm:
- One size doesn’t fit all: We ended up using width (i.e. number of trees) and maximum depth hyperparameters that were very different from anything we had seen in academia or online. While tuning these parameters, we learned to view width as an enabler of depth in a rehashing of the classic bias-variance tradeoff. Effectively, we realized that increasing width led to improved variance, while increasing max depth led to improved bias.
- Don’t split small leaves: While we view the size of a forest as a lever on model variance, we actually found maximum depth to be a poor means of controlling it because of the imbalance of typical decision trees. So instead of relying on a maximum depth, we aggressively halt the growth of a branch when the number of samples in a leaf drops below a set threshold. This same approach is recommended in scikit-learn’s documentation, and has worked well for us.
- Gini impurity works best for classification: We began our experimentation using variance reduction to measure split quality, but eventually found the Gini impurity measure to work best. This made intuitive sense for us as the sum of squares and square of sums terms used to compute variance are always equal for binary outputs (i.e. our two “labels” are just 0 and 1, both of which equal their square).
4. Evaluation optimizations
We also discovered some interesting optimizations for evaluating decision forests:
- Smoothing predictions: Instead of using the “raw” prediction (i.e. predicted fraud rate) from a leaf node as the contribution from each decision tree, we take the weighted average of the leaf node with its parent node. Here the weight in the weighted average is the number of samples in each node. The intuition behind this optimization is that we still end up with some leaf nodes with very few samples despite the aforementioned restriction to only splitting on leaves with sufficient samples. We saw a significant accuracy boost from this change.
- Using a logistic function to improve separation: About a month before we launched decision forests, we were in a place where they were significantly improving the accuracy of our modeling stack as measured by area under the ROC curve, but with poorer class separation in absolute terms. Class separation is important for making Sift scores actionable to customers. We applied a simple logistic function (Figure 3) to the output of every decision tree prior to averaging its prediction in order to produce the forest’s prediction.
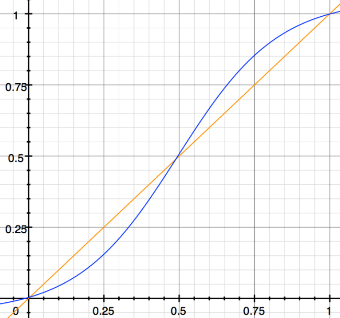
We found this to work well for improving the class separation of scores produced by our model, and even resulted in a slight accuracy boost.
5. Performance optimizations
While building out our own decision forest trainer – modeled after Google’s PLANET paper – we learned several interesting optimizations. It’s useful to first clarify our requirements of the training algorithm. We needed to train a decision forest:
- with hundreds of trees
- to a depth of 20 or greater
- over 10s of millions of samples each with 500+ features
- in a few hours
- without increasing our infrastructure costs
Given these requirements, we made a few modifications to the original PLANET paper:
- Learn splits for many nodes per job: Google’s paper describes an algorithm that only learns the optimal split for a single node per MapReduce job. Given the size of the forest to be trained, this wasn’t feasible for us, so we instead distribute all split learning across a handful of jobs for every level.
- Approximately correct candidate splits are fine: The candidate split selection phase of PLANET is run prior to learning the best split for any node and is used to restrict the number of different splits considered for each node. We found through experimentation that the candidate splits learned in this preliminary phase don’t need to be too precise; in fact, we didn’t see any reduction in accuracy when building the candidate splits based on a random sample of 1% of our training set. This idea is taken even further by Extremely Randomized Trees (Geurts 2006), where the authors propose a decision forest learning algorithm that randomly selects candidate split points.
6. Visualization is key
As anyone who has worked with a machine learning model in the real world can attest to, being able to visualize the final model you have trained is invaluable. At Sift, we had already recognized this through the process of building our other ML models, so we planned to build a human-readable visualization of our decision forest model early on.
The first form of visualization we built was a very dense text-only view of a decision forest:

While this representation is rather ugly and hard to understand at first glance, it manages to present 100% of the information in our finished models, which allows us to more easily debug issues in our training algorithm. It has the additional benefit of working well with standard text manipulation tools such as grep and diff, which has helped us catch quite a few bugs in our training algorithm.
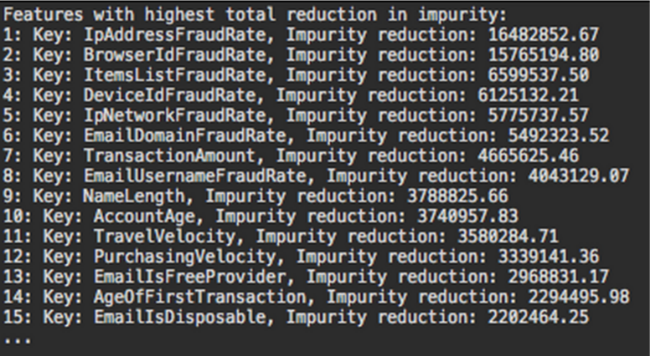
Moving beyond debugging a model, we also like to have an accurate way of measuring the impact of each individual feature on a model. For decision forests, we ended up adding a few such methods. The first (Figure 5 below) ranks all features by the total reduction in impurity each induces across the entire forest. This metric has proven to be a reliable way to measure the impact of a feature on our decision forest model:
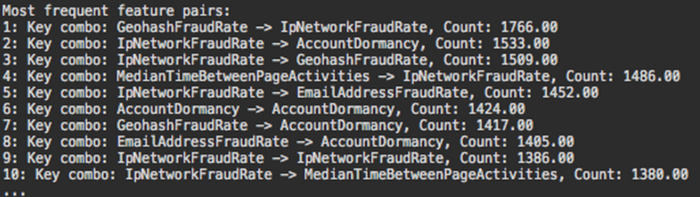
We also built out a ranking of the most frequent feature pair combinations seen in the model (Figure 6 below). This ranking isn’t too useful for deciding whether a feature should be added to our model or not, but is interesting to look at to get a sense for what is going on “inside the mind” of a decision forest model.
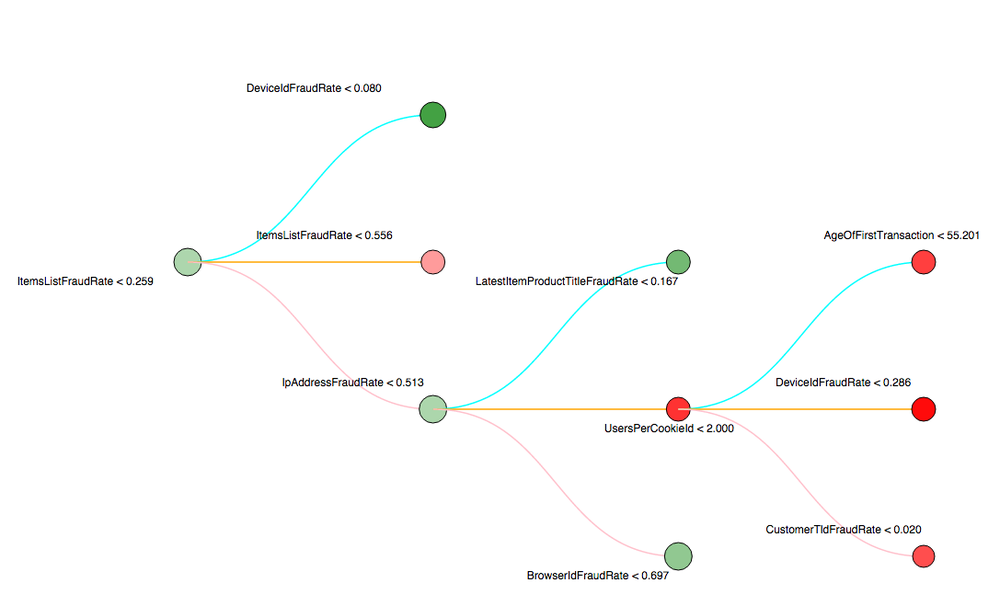
The latest addition to our fleet of decision forest visualization tools is a D3 based interactive view of a single decision tree (Figure 7). This visualization is most useful for digging into specific paths of a single tree to understand its behavior.
7. No model is uniformly better
When we first began the project to add decision forests to our modeling stack, we thought the change to our modeling stack would look like this:
However, after months of experimentation, we realized that even though our decision forest model was outperforming our logistic regression model in aggregate, there were still some cases (customers, features, users, etc.) where logistic regression outperformed decision forests. In a nutshell, every model has its own unique strengths and weaknesses. After coming to this realization, we decided to move forward with a modeling stack that looked like this:
Combining all of our models together in our modeling stack far outperformed either modeling stack seen in the Figure 8. Our belief now is that our decision forest model is best at learning about complex behavioral patterns whereas our logistic regression model is superior at learning over sparse features. This leads to scores from each of these models being de-correlated with one another, lending themselves well to being mixed together.
Results:
Prior to the above learnings, our initial “stock” decision forest model was actually performing significantly worse than our logistic regression model in offline experiments. After going through the arduous process of learning the above lessons, however, we were able to train a decision forest model that significantly improved overall accuracy to the tune of 18%. But the benefits of adding a decision forest model to our stack don’t end there; now that our modeling has received a serious upgrade, we have that much more room to grow with our feature engineering. We’ve already begun taking advantage of this new expressivity by experimenting with customer level features — features that can effectively use decision forests to cluster our customers and learn separate sub-trees for each of them. Beyond that, we now also have the exciting challenge of updating our decision forests online ahead of us.
Conclusion:
In conclusion:
- Decision forests make for a powerful, scalable, and intuitive model
- There’s much to be gained by going beyond “standard” DF implementations
- Understanding and visualizing a machine learning model at a deep level provides huge benefits
10 Comments
August 27, 2015 at 3:44 am
hi, I really appreiciate your works. But i am very curious about how do you get all these model emsembled in your stack. Can you explain it?
August 28, 2015 at 11:33 pm
Hi aromazyl,
We combine the component models mentioned above in varying ways depending on the amount of data we have for each customer, but without deeper context on our modeling problem and data model it’s kind of hard to properly explain. The high level techniques, however, are not too different than typical ensemble model combination strategies (e.g. mean of probabilities).
August 27, 2015 at 7:04 pm
Regarding your handling of sparse features: your approach assumes that we can attribute all y-variation correlated to zipcode to this one group feature, and all the remaining variables only model the variation within the group. However, different hierarchies can be defined and I am not convinced we can arbitrarily use your approach for any categorical variable
August 28, 2015 at 11:38 pm
Hi paman,
Our approach does indeed make some large simplifying assumptions, but we actually have supplemental feature engineering in place (not mentioned in the post) that allows us to more easily learn arbitrary hierarchies of categorical features for those features that are "less sparse" (e.g. a country code). The combination of this with the fraud rate approach outlined above worked better for us than any other method of using sparse features with decision forests.
August 28, 2015 at 10:46 am
Excellent post and thanks for sharing. It makes absolutely sense to use random forests (vs logistic regression) and to use parameter values such as described in section 5 in the post. See https://github.com/szilard/benchm-ml for a comparison of accuracy, scalability and speed of various open source implementations of top classification algorithms on a dataset of similar size and structure. I wonder if you can share some performance results of your own implementation vs commonly used open source tools, especially in light of comments by the Databricks/Spark/MLlib folks here https://datascience.la/benchmarking-random-forest-implementations/#comment-53599 concerning performance issues (speed and memory footprint): "The main issue with MLlib’s tree implementation is that it is optimized for training shallow trees, following the PLANET project. We’re working on an alternative implementation geared towards training deep trees". Thanks again for blog post. -Szilard
August 28, 2015 at 11:45 pm
Hi Szilard,
I’m glad you enjoyed the post. Thank you for sharing the link, there’s some really interesting stuff in there. I can’t speak too much to MLlib’s implementation, as I haven’t read through their code, but I do know that we saw significantly worse accuracy using their stock decision forest trainer compared to ours and that their trainer took somewhat longer than ours to complete. I think both of these outcomes are to be expected, as we have done a considerable amount of work optimizing our model for our specific use case.
August 29, 2015 at 4:21 pm
Thanks Alex for reply. What about the top performers in https://github.com/szilard/benchm-ml (H2O, xgboost)? DM me for example via Linkedin https://www.linkedin.com/in/szilard
August 31, 2015 at 5:23 am
Unfortunately I’m not too familiar with either H2O or xgboost so I can’t really give a comparison of our setup to theirs. However, I will say that it’s not really fair to compare our implementation (or Spark’s) to scikit-learn’s or R’s, since our implementation is designed for very large datasets in a distributed setting whereas the Python and R implementations are assuming the dataset will fit into memory.
August 30, 2015 at 10:05 pm
Thank you for an excellent article
How do you use your model in production?
Do you translate tree descriptions to java/c++/bytecode/machine code or how?
August 31, 2015 at 5:12 am
Hi Andrei,
We have a custom format for persisting decision trees on disk and use an adapter in Java to reading this format.