ML Experiments at Sift Science, Part 1: Minimizing Bias
At Sift Science we use machine learning to prevent various forms of abuse on the internet. To do this, we start with some data provided by our customers:
- Page view data sent via our Javascript snippet
- Event data for important events, such as the creation of an order or account, sent through our Events API
- Feedback through our Labels API or our web Console
We then combine this data with a few external data sources and use it to train a variety of models to produce scores for 4 distinct abuse prevention products (payment, promotion, content, and account), which are then accessible through Workflows and our Score API:
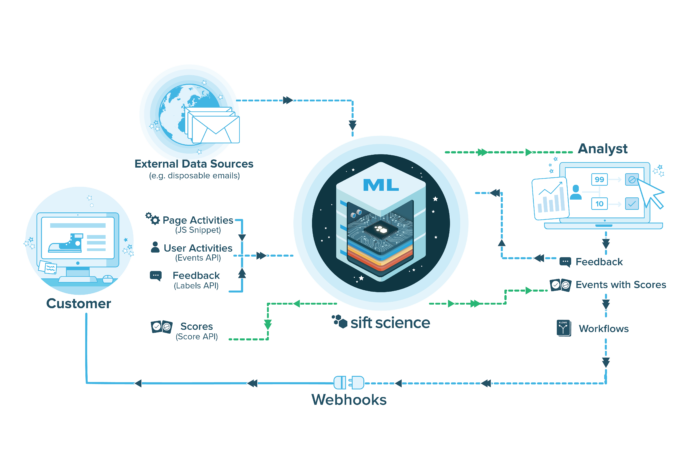
Improving the accuracy of these scores leads directly to more revenue, less fraud, and better end-user experiences for our customers. Therefore, we spend a large amount of effort trying to improve our machine learning’s accuracy. In this three part series on ML Experiments at Sift, we’ll discuss some lessons we have learned around building an ML experimentation framework that allows us to do this effectively. This post begins the series by describing how we minimize bias in offline experiments.
Running Experiments Correctly
A useful experimentation framework must allow its user to quickly run an experiment and gather its results while introducing as little bias as possible. At Sift, this is particularly difficult because of the long feedback delay we typically see. The worst case of this is with payment fraud, where feedback is usually in the form of a chargeback, which can take up to 90 days to make its way to us:

Outside of payment abuse, our other abuse products still typically require hours or days to receive feedback. Because of this, we can’t use live A/B tests to measure the effect of a change to our system.
The problem then becomes: how can we run offline experiments that correctly simulate the live case? Below we present some of the issues that make this a difficult problem along with the approach we have taken to address them.
Train-test set creation
The first challenge we faced when constructing our experiments was determining how we should construct our training, validation, and testing sets (each of which consists of a collection of user Events which we would have scored in the online case). While doing this, we found:
- Sets need to be disjoint in time. One of the strongest aspects of our ML is its ability to accurately connect new accounts to accounts previously known to be associated with fraud. Therefore, we require that all data in the training set occurred prior to the validation set, and that the validation set occurred prior to the testing set.
- Sets also need to be disjoint in user-space. We don’t want to give ourselves credit for correctly identifying known fraudulent accounts as being fraudulent, as this provides no value to our customers, so we need to ensure that each end-user only appears in a single set. This gives us a train-test set split that looks like this:
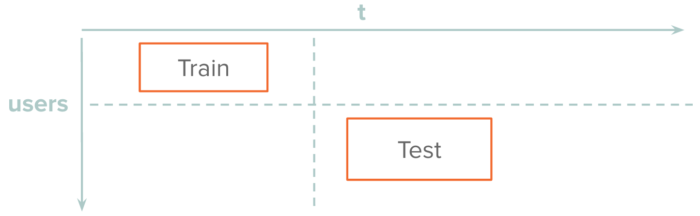
- Class skew is problematic. Our typical customer only sees fraud or abuse in roughly 1/50th of all transactions/posts/etc., so to ensure we don’t train something close to the always-negative classifier we have to heavily downsample the not-fraud class.
Preventing cheating
A challenge that we continually face is preventing our models from “cheating” in offline experiments by using information that would not be available to our live system (e.g. anything from the future). A simple case of this was already discussed above when we talked about our train/validation/test sets being disjoint in time. However, this problem surfaces itself in more subtle ways in our system, which has led us to take the following precautions:
- External data sources need to be versioned. We leverage a number of third-party data sources in our system, such as IP-Geo mappings and open proxy lists. When running offline experiments, we need to ensure we only ever use the latest version of these data sources available at the point in time at which we are extracting features for a user:

- Verify all new data sources are not biased in any way by ground truth. In addition to ensuring external and derived data sources do not leak backwards in time, we also need to make sure the collection of these data sources is not a function of the labels we have collected. For example, when backfilling some new data source from historical data, we can’t bias the backfill process towards more aggressively backfilling data for users belonging to the positive (i.e. fraudulent) class. We have run into this exact issue in the past when experimenting with third-party social data sources, which led to some too-good-to-be-true initial results. Since then, we have learned to more thoroughly vet all new data sources introduced into our pipeline, including the more recent introduction of an email age feature which is derived from our customers’ data.
Parity with the live system
Closely related to preventing cheating in an offline system, we’ve also put special effort towards maintaining parity between the offline and live systems whenever possible. The simplest lesson here is to aim to reuse the same code paths online and offline; this helps to minimize the surface area where potential bugs and biases could creep into the offline system.
However, creating an offline simulation necessitates a large amount of code that won’t be shared with the online system, such as the machinery required to play back all feedback in the proper order to support online learning. We’ve found that parity tests, as well as an easily decomposable pipeline, can be quite useful in ensuring the offline system behaves as intended.
Measuring value to customers
Beyond ensuring the models are trained and evaluated in a correct manner, we also need to pay attention to how closely our evaluation techniques match how our customers use our product. For our Payment Fraud product, this means we only evaluate our ML using the scores given at time of checkout, while for the Content Abuse product we only use the scores given at the time of a post being created.
For example, consider the following sequence of events and scores:
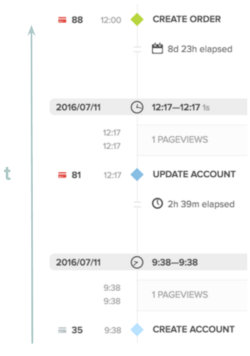
If in this case the customer used the score at time of the Create Account event to determine if the user should be allowed to create the account, then the score of 35 is the one we should use to evaluate our accuracy. That is, if the user eventually ended up being labeled with a positive Account Abuse label, then we should not get credit for giving the user a higher score after the Create Account event. This ensures a positive change in our evaluation metrics actually correlates to a positive change for our customers.
Key takeaways
To summarize, conducting representative and bias-free offline experiments can be challenging, and special attention needs to be paid to:
- Train-test set creation, to ensure models are trained towards the proper objective.
- Preventing cheating, to ensure evaluation of experiments is directionally correct.
- Maintaining parity with the live system, to ensure experiment results more closely correlate to live results.
- Experiment evaluation, to ensure experiments properly measure value to customers.
In the next post in this series, we’ll go over some pitfalls in comparing the results of two experiments as well as some lessons we have learned towards more effectively and correctly performing such comparisons.
Can’t get enough machine learning? Come fight fraud with us!